
TTY-changelog #034
Autonomous research agents go viral and spark debate on what counts as real novelty, coding workflows clash over terminal vs IDE tradeoffs, and plant genomics gets open foundation models.

👉 Article originally posted on TTY
Events
🇫🇷 Gemini 3 Paris Hackathon (March 14) – Cerebral Valley and Google DeepMind hackathon in Paris. Builders competed on Gemini 3 across AI Studio, Vertex AI, and Antigravity for 150K in API credits.
🇫🇷 Mistral AI NOW SUMMIT in Paris (May 28) – Mistral’s flagship conference with sessions from Mistral and global leaders building and deploying AI at scale. Ticket and content details remain limited.
Community Ask
📝 White paper on AI coding frontiers – A community member began assembling a white paper interviewing engineers at the frontier of coding-agent workflows, seeking real practices, unusual setups, and hard-won lessons rather than generic opinions. The project targets engineers who feel mainstream AI coding discourse lags behind their actual practice. 👉 DM Noe Charmet
Autonomous Agents
🧪 Karpathy’s Autoresearch went viral – Open-source tool automating research on single-GPU nanochat training, generating and evaluating experiments autonomously. The project gained viral traction over the weekend for its simplicity and effectiveness.
🔥 Community take from our BioTechLunch: Many compare it to existing approaches such as hyperparameter search or evolutionary algorithms, noting that its novelty lies more in accessibility and scale than in fundamentally new methods. Its main value may be in allowing researchers to continuously explore numerous small ideas or improvements in the background while they focus on higher level problems. However, several concerns have been raised about metric gaming and overfitting if evaluation criteria are poorly defined. Overall, the consensus is that AutoResearch is best viewed as a research assistant that scales experimentation, while real progress in fields like biology still depends primarily on better data and experimental validation.

👍 Can AI agents reach consensus? – The paper shows that groups of AI chatbots struggle to reliably agree on a single number, even when they do not care which number wins. Larger groups fail more often, and adding a few malicious agents causes stalls and timeouts. This suggests current multi-agent LLM systems are not yet dependable for robust coordination.
🕵️ Agents reproduce worst human social behaviors – Autonomous AI assistants with email, chat, files, and code access can be tricked into leaking secrets, obeying strangers, wasting resources, breaking their own systems, or spreading manipulation, so they need much stronger security and oversight before real-world deployment.
📊 SWE-CI benchmarked agent code maintainability – The benchmark tests how well AI coding agents maintain and evolve real Python projects over many commits, mimicking a continuous integration workflow. It uses 100 real repo histories and a dual Architect–Programmer agent loop plus a new EvoScore metric to reward long-term, low-regression code quality rather than one-shot bug fixes.
Biotech, Health, and Chemistry
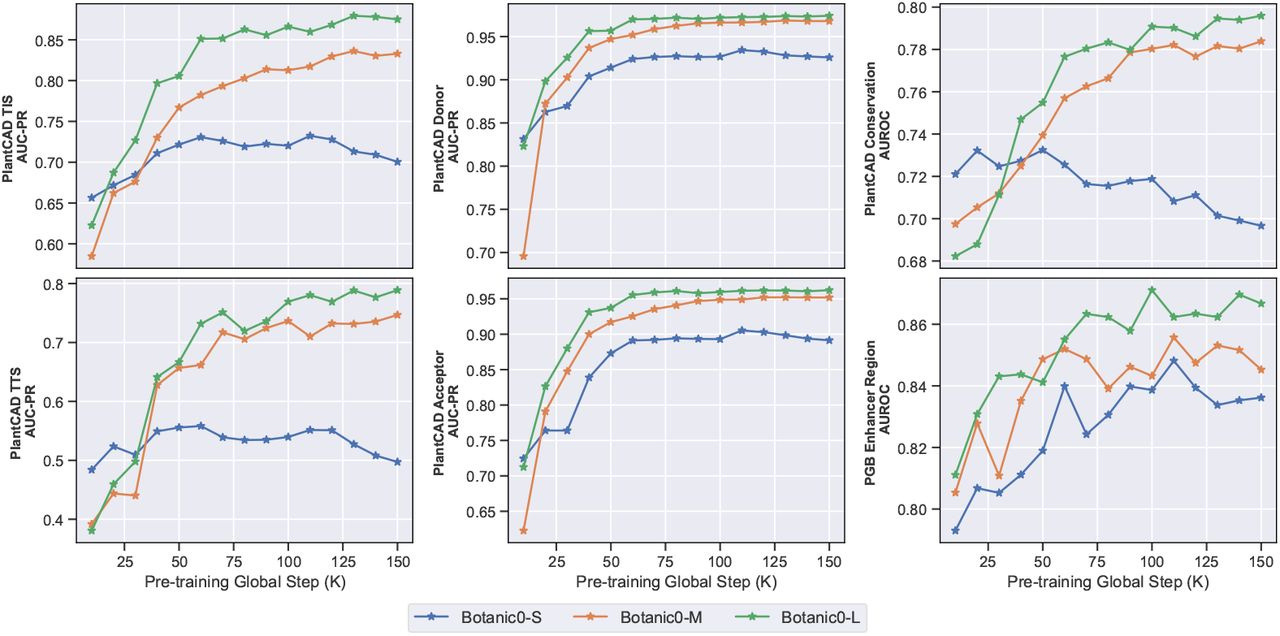
🌱 AI “Language Models” for Plant DNA - Alongside their Seed round, Living Models released genomic language models called Botanic0 that learn patterns directly from plant DNA to support predictions of gene activity and mutation effects, with larger models performing better and all models released openly for crop research.
Three model sizes (100M–1B params) trained on DNA from 43 plant species.
Perform on par with or better than other top plant DNA models on many benchmarks.
Can rank harmful vs neutral mutations without task-specific training.
Useful as general DNA embeddings and can be fine-tuned for specific genomic tasks.
Image, Video & 3D
🎬 Netflix acquired AI filmmaking startup – The streaming giant made a rare acquisition of InterPositive, Ben Affleck’s startup building AI-powered tools for filmmakers, signaling deeper integration of generative AI into professional production workflows.
Language Models
📋 SkillsBench: human skills beat autogenerated – Benchmark evaluated the impact of reusable skill instructions on LLM agent performance, finding that human-authored skills significantly boost reliability while autogenerated ones offer only marginal gains. The results challenge the assumption that agents can self-improve through automated skill generation.
🧪 LLM bullshit benchmark viewer – Interactive tool for browsing and comparing LLM evaluation results across models, providing a visual interface to explore benchmark performance data. The viewer aggregates results across multiple evaluation dimensions for side-by-side model comparison.
MLOps
⚡ Autokernel automates GPU kernel optimization – RightNow AI released an open-source tool that automates CUDA kernel optimization through iterative agent loops guided by a detailed instruction set. The project mirrors Karpathy’s autoresearch philosophy, applying simple agent patterns to compute-heavy tasks.
Programming
🎁 Opus defaults to 1M context window – Claude’s newest Opus 4.6 and Sonnet 4.6 models can now read about 1M tokens (huge files and chats) at normal prices, with higher limits for images/PDFs and no special beta setup needed.
🔍 Argus: Claude Code session debugger – Open-source tool for debugging and analyzing Claude Code sessions, providing performance insights and visibility into agent behavior during coding workflows.
⚖️ CLI vs IDE agent debate – Amp dropped its editor extension to focus entirely on terminal workflows, sparking discussion on whether removing IDE integration sacrifices code review quality. Amp podcast
🔥 Community take: Opinions were mixed. Some flagged invisible quality decay as the real risk: agents produce files that build and pass but accumulate junk, bloated components, and inconsistent naming that nobody catches without visual review. The pragmatic fix shared was running the agent in terminal while staging files in a side editor as a “reviewed” gate, with a dedicated local diff review tool for this workflow. Others argued the concern is already outdated as bigger context windows and tool improvements are actively closing the gap.
🔥 Community events:
🧩 Pipelex shipped MTHDS workflow language – Open-source framework (say “Methods”) introduced a typed, declarative language for defining executable AI methods with validated inputs and outputs. Ships with a Claude Code plugin, interactive VS Code extension, multi-provider gateway, and package manager. Hub Claude Code plugin Runtime
🗜️ Edgee shipped lossless Claude token compression – Fully lossless compression of tool call results for Claude Code and tool-heavy Claude workflows, extending effective context limits by 26.5% without information loss. Useful for teams hitting Claude Code rate limits on tool-heavy agentic sessions.
🗜️ Headroom: OSS context compression layer – Open-source context optimization framework for LLM applications surpassed 700 GitHub stars and launched a Discord community. The project focuses on prefix caching improvements to reduce token usage across agentic workflows.
📊 Claude Code subscription community survey – A community poll revealed diverse approaches to Claude Code licensing. Most teams split between Individual Max and Team Premium, with some combining tiers by role and supplementing with API or Bedrock access.
Heavy users typically run Individual Max 20x while junior team members and non-developers use Team Premium.
Larger teams (20+ users) prefer Team Premium for unified billing, while sub-5-person teams rely on individual plans.
Several members supplement subscriptions with pay-as-you-go API access or AWS Bedrock for specific capabilities.
Reinforcement Learning
🎓 KARL: RL-trained enterprise search agents – KARL is a training method that teaches AI search agents to find, combine, and reason over company data much better and cheaper than current top models, using synthetic practice data and reinforcement learning.
The (BioTech) Lunch

This week with Ashley van Heteren, Cyril Véran, Jean du Terrail, Félix Raimundo, Ihab Bendidi, Jeremie Kalfon, Julien Duquesne, Maziyar Panahi, and Pierre Manceron (Raidium), we discussed:
AutoResearch from Karpathy
Data, the real bottleneck in computational biology
The LLM versus world model approach
The TechBio business models and failures
The AI Coding Dinner w/ Ctrl+G

Co-organized with Grégoire Gambatto and Paco Villetard (Ctrl+G) we had Aymeric Roucher, Benjamin Trom, Hugo Venturini, Amine Saboni, Adam Surak, Louis Choquel, Gregory Tappero, Grégoire Mialon. Our discussion was mostly about:
Persistent agents (OpenClaw legacy)
SkipLabs: Static analysis meets LLMs
The impact of code explosion on teams
How to rethink engineer interviews
New Member
🇫🇷 Hugo Venturini – Software Engineer @ SkipLabs · Building a controlled, governed environment for a dedicated AI coding agent leveraging static analysis tooling. Father of three, bouldering climber, jazz piano amateur at the Bill Evans Piano Academy, and whisky ex-connoisseur. Has written songs for a French singer working on his fourth album. Special power: pending consultation with his kids. 📍 Paris, France
Contributors This Week
Kevin Kuipers, Amine Saboni, Louis Choquel, Hugo Venturini, Tejas Chopra, Leonard Strouk, Felix Raimundo, Mehdi Medjaoui, Gabriel Olympie, Sacha Morard, Noé Charmet, Pierre Chapuis, Sylvain Hajri, Alex Zhuk, Thierry Abalea, Quentin Dubois, Robert Hommes, Benoit Kohler, Maxence Maireaux, Gert Lanckriet, Karim Matrah, Kemal Toprak Uçar, Koutheir Cherni KC, Nikolay Tchakarov, Victoire Cachoux, Lucas DiCiocci, Julien Duquesne, Omid Gosha, Julien Millet, Jules Belveze, Anicet Nougaret, Anselme Trochu, Guillaume Lesur, Christophe Lesur, Enrico Piovano, Antonin Lacombe, Jocelyn Fournier, Gawen Arab, Arnaud Porterie, Marek Kalnik.