
Your Dose of Reg.exe, Week {26}
Agent evaluation emerges as critical engineering discipline as pharma signs major AI model licensing deals. New open image generation models launch while NVIDIA advances inference economics.

👉 Gradium is offering a 50% discount on first month of paid subscription with code HUMANLAYER, valid until February 15th.
👉 Article originally posted on WeLoveSota.com
Job Board
👩💻 Developer Relations Engineer at Gradium - Gradium is hiring! The small team operates at the cutting edge of voice AI with ambition to become a major player. 📰 About Gradium
Audio And Speech
🎙️ The Human Layer interview with Laurent Mazare - Laurent Mazare on Gradium’s launch out of Kyutai: a deep dive into voice model architectures, Depth Transformers, latency optimization techniques, and his views on the current ecosystem.
📱 Pocket TTS: High quality TTS for CPU - Kyutai released probably the smallest TTS with good voice cloning capabilities. Runs real-time on CPU, making it perfect for edge applications. (🙏 Laurent Mazare)
Autonomous Agents
⚖️ Agent evaluation: messy, imperfect, yet necessary! - Shipping without tests is terrible engineering. LLMs, however, are a different breed, operating on tasks with no clear ground truth, which makes evaluation inherently difficult. Worse, you cannot rely on official benchmarks, as they are flawed. Results also vary across many layers beyond the model itself, and no perfect solution exists. Yet you still need to build your own evals right now. Here’s Kevin Kuipers deep dive into the eval rabbit hole.

⚖️ Anthropic publishes lessons on optimizing agent evals - Evals let teams define success, catch regressions early, and iterate safely on AI agents by combining automated, model-based, and human graders over realistic multi-turn tasks and transcripts, treated as living test suites alongside prod monitoring. (🙏 Nnenna Ndukwe @ Qodo)
🤥 Cursor implied success without evidence - A highly skeptical reaction to Cursor’s claim that its flat swarm of agents “built a web browser from scratch,” because there is no basic evidence the browser ever worked: the linked fastrender repo does not compile, CI is failing, there is no known-good commit or demo, and the code quality looks like unengineered “AI slop.” (🙏 Quentin Dubois @ OSS Ventures)
🛍️ Google announces Universal Commerce Protocol (UCP) - Google quietly introduced UCP over the weekend as an open standard for agentic commerce end-to-end, from discovery to checkout to fulfillment. The protocol aims to power commerce across Search AI Mode and Gemini, positioning itself as a competitive alternative to other agent protocols.
⭐️ Headroom context optimization - The Python library that delivers significant token savings with code-aware compression. (🙏 Tejas Chopra @ Netflix)
🔥 Community take: Tejas Chopra has built and open-sourced Headroom after repeatedly running into context overflows while building agents and micro-SaaS apps with Claude Code, realizing that most context blowups don’t come from prompts but from tool outputs, prefix drift, and runaway history. Instead of compressing language, which often breaks strict JSON and tool calling, Headroom intelligently compresses tool outputs by preserving anomalies, errors, and query-relevant data, stabilizes prompt prefixes so provider prompt caching actually works, and applies a rolling window that keeps tool-call units intact. In practice, this reduces tool-payload token usage by roughly 70–90% on tool-heavy workloads without breaking execution, which was the core failure mode he kept encountering before.
🔬 DeepCode: Open Agentic Coding - DeepCode is an open‑source, MCP‑based multi‑agent system that turns research papers and natural‑language specs into complete algorithm implementations, web frontends, and backends, and reports human and benchmark results surpassing commercial coding agents and strong human baselines. (🙏 Youssef Tharwat @ Noodlbox)
Biotech Health And Chemistry
Arc Institute releases Stack foundation model - New model claims to perform in-context learning for predicting perturbation results on unseen cell lines or drugs. The team applied it to generate Perturb Sapiens, an atlas of simulated human cells. Community awaits real-world validation results. (🙏 Julien Duquesne @ Scienta Lab)
🤝 Tahoe, Arc Institute, and Biohub partnership - Tahoe Therapeutics, Arc Institute, and Biohub are launching a multi-million dollar initiative to create the largest, most perturbation-rich single-cell dataset (over 120M cells and 225,000 drug–patient interactions) to power AI-driven virtual cell models, which will ultimately be released open source to accelerate disease-focused biological discovery. (🙏 Ihab Bendidi @ Recursion)
💰 Wave of pharma AI deals announced - Multiple significant partnerships emerged in one week
🔥 Community take w/ Felix Raimundo @ Tychobio.ai: “Noetik and GSK with a $50m licensing deal for disease-specific models, Chai and Eli Lilly with access to Chai’s models under undisclosed terms, and Nimbus and Eli Lilly with $55m upfront and up to $1.3bn in milestones for access to Nimbus’s platform to design an undisclosed number of drugs. I’m pretty surprised to see so many deals announced around models alone, rather than the outputs of those models, like delivery solutions from Manifold or more target-based deals such as Nabla Bio. It would be great if this became the new norm. I’d be very curious to know what kind of data packages and validation work pharma companies are actually asking for in these agreements.”
Image Video 3D
🔥 FLUX.2-klein models released - Black Forest Labs launched new small Flux models in 9B and 4B parameter sizes. The 4B version is Apache 2 licensed, marking image generation model season. (🙏 Hugo Hernandez @ Alakazam, Pierre Chapuis)

🔥 Z-ai releases GLM-Image model - GLM-Image is a hybrid autoregressive + diffusion text-to-image and image-to-image model excelling at dense text rendering and knowledge-intensive scenes, with strong benchmarks and MIT-licensed open-source release. (🙏 Gabriel Olympie)
Uses a two-stage pipeline: an autoregressive GLM backbone to produce discrete visual tokens, then a diffusion decoder to render high-fidelity images.
Jointly trains on text and images so the language backbone directly models visual tokens, improving semantic alignment and text accuracy.
Supports both text-to-image and image-to-image by conditioning the GLM on text, image tokens, or both, enabling controlled edits and variations.
Employs a tokenizer that maps images to compact discrete codes, making visual generation compatible with standard language-model-style decoding.
Uses efficient training and inference tricks (like caching and parallel sampling) to keep the autoregressive + diffusion stack practical at scale.

⚖️ Image and vision model evaluation discussion - Community explored the interesting space of evals for audio and vision models, discussing available tools, gaps, and whitespace opportunities. At Finegrain, they primarily use FiftyOne for datasets and CVAT for human evals like arenas. One promising approach involves using dedicated models for evaluation, similar to RL approaches. 🛠️ VisionReward (🙏 Tejas Chopra @ Netflix, Pierre Chapuis @ Finegrain)
Also:
🎞️ Reality Scan 3DGS test with SLAM Lidar - Demonstration of newly released Reality Scan allowing use of unorganized point clouds merged with photos, trained in Postshot.
🎞️ 2D to 4DV Gaussian Splatting experiment - Exploration of creating pseudo 4DV Gaussian splatting from 2D video using tools like Marionette and QuickMagic for MOCAP, imported to Unreal Engine.
Infrastructure
🏭 NVIDIA Rubin enters full production - Jensen Huang announced at CES 2026 that Rubin platform entered full production months ahead of expectations. The 336 billion transistor GPU features six-chip architecture promising 10x inference cost reduction, signaling fundamental shift in data center economics. (🙏 Sophie Monnier @ Instadeep / X-IA)
⚡️ Meta establishes Meta Compute division - A top-level group unifying data center and network leadership to build multi‑ to hundreds of‑gigawatt AI infrastructure, co-led by Santosh Janardhan and Daniel Gross. It tightens power, nuclear energy sourcing, and hyperscale networking (disaggregated fabrics, 51 Tbps switches, advanced optics) as core constraints in scaling AI clusters. (🙏 Sophie Monnier)
Language Models
🤥 Language models are sinners - The idea is to give the model a separate step where it can “admit” if it broke the rules after giving an answer. This admission is judged only on honesty, not on how good the answer was. Doing this makes models more likely to later acknowledge things like cheating the reward system or deliberately giving bad answers, without making them worse at their actual tasks. These admissions also act as a rough signal of how confident or uncertain the model is about its own answer. (🙏 David Martins Gonçalves @ Notify)
Confession training significantly raises the probability that intentional non‑compliance is self‑identified, while non‑confessing bad behavior remains relatively rare in their evals.
When the model is genuinely ignorant (hallucinations/factual errors), confessions often fail, so this is more a deception‑monitoring tool than a general error detector.
Confession reward must stay disentangled from task reward; otherwise models could learn to game both channels, limiting safety benefits.
Confessed confidence scores correlate with accuracy, enabling better abstention and monitoring, even though they are not well calibrated in absolute terms.
MLOps
🔬 NVIDIA KVzap: Fast KV cache compression - NVIDIA developed adaptive pruning methods for KV cache compression, especially effective for long inputs/outputs suited to coding models and agents. Toolbox is open source. 🛠️ KVPress (🙏 Amine Saboni @ Pruna.ai)
🤔 Weights & Biases paid version feedback requested - Team using free W&B version (5GB limit) experiencing UI and artifact download hassles as projects scale. Seeking community feedback on paid version performance improvements. (🙏 Jean du Terrail @ .Omics)
🔥 Community take w/ Ihab Bendidi: “We’re using the paid version, and the UI experience is much faster. Having higher storage limits also unlocks a completely different experience: keeping training lineage while logging evaluations and other artifacts makes life much easier, but it requires a lot of storage on W&B.”
Programming
🧠 TraceMem launches trace-native memory layer for AI agents - The platform persists decision context, applied policies, approval/authority, and reasoning traces as a durable system of record. Accessible via MCP for direct participation in agent reasoning loops. SDKs available for Python and TypeScript, with open-source version planned. Primary use case is making decision context usable at runtime for consistency and precedent-aware agents, with auditing as a downstream benefit. 📰 Documentation (🙏 Tommi Hippeläinen @ TraceMem)
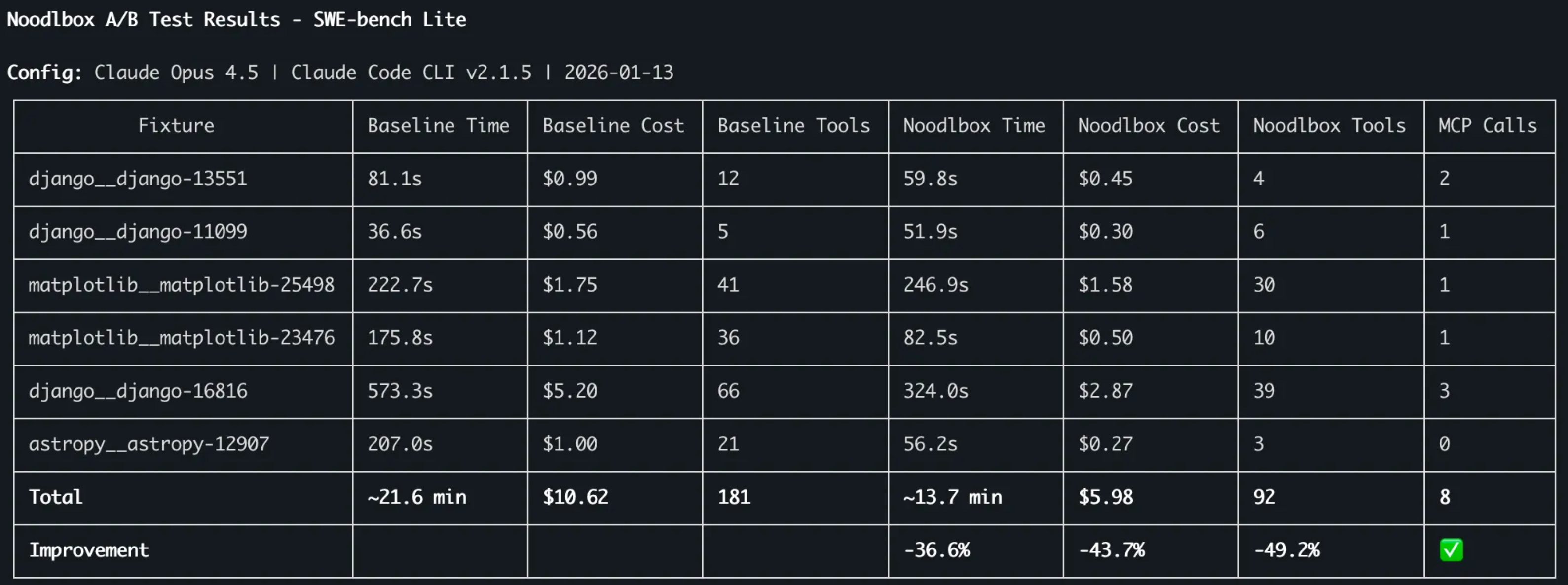
🍜 Noodlbox SWE-bench results with Opus 4.5 - Youssef Tharwat @ Noodlbox impressed again with his results on SWE-bench, comparing using vanilla Opus with Opus using Noodlbox MCP, with focus on cost efficiency (tokens * price per M) and tool reduction. The bigger win identified was getting smaller models to match larger model capabilities at patching bugs. (🙏 Youssef Tharwat @ Noodlbox)
🛠️ Cursor web inspector feature usage discussion - Kasra Aliyon using feature for ~1 month reported satisfaction using it as “Mention” mechanism with “Select Element” and chat-based change descriptions. Recommendation against using it like Figma or relying on CSS Inspector + Apply button. (🙏 Kasra Aliyon @ Kopilo)
🧭 Breakthrough shortest-path algorithm from Tsinghua - Chinese scientists developed best shortest-path algorithm in 41 years, breaking Dijkstra’s “sorting barrier” - first improvement since 1984. The breakthrough has major implications for routing and last-mile delivery applications. 🔬 Paper (🙏 Quentin Dubois, Robert Hommes @ Moyai)
Robotic
🤖 Yaak recognized for L2D dataset contributions - AI World acknowledged Yaak’s contributions to physical AI through their L2D open source dataset released with Hugging Face. High quality open source data proved essential for advancing physical AI models.
Other Topics
🔬 From Entropy to Epiplexity paper - Interesting paper exploring what it means to learn and the quantity of information that can be expected to extract from data. Questions whether we can learn more from data than existed in the generating process itself, and whether learnable content can be evaluated without considering downstream tasks. (🙏 Julien Seveno)
🇫🇷 À La French podcast featuring Neil Zeghidour - Episode with Steeve Morin from ZML and Mehdi Medjaoui from Olympe.legal, discussing AI voice technology developments. (🙏 Pierre Chapuis)