
Your Dose of Reg.exe, Week {21}
Claude Opus 4.5 lands as Anthropic's most capable model yet, Ilya Sutskever declares the scaling era over, and Depth Anything 3 sets new standards for 3D scene understanding.

👉 Article originally posted on WeLoveSota.com
Our Posts
🕹️ Deep dive on AI impact in gaming industry - While gamers loudly resist AI, studios are rapidly adopting it as a behind-the-scenes productivity layer, especially for code, tools, and pipelines rather than visible art or voices. (👉 Kevin Kuipers)
🏦 Startups Are Winning Enterprise AI: Enterprise engineers often treat AI with skepticism, but founders, facing very different incentives, embrace it as a leverage tool for shipping products quickly. (👉 Willy Braun)
🧑💻 Ivan Yamshchikov, The Radical Techno-Optimist - Ivan from Pleias argues that open, transparent AI with small, specialized models and carefully shaped synthetic data will beat brute-force scaling. (👉 Kevin Kuipers)
Events
🇫🇷 TechRocks Summit, Paris - December 1-2 - Event for CTOs and Tech Leaders at Théâtre de Paris. Two days of no-bullshit conferences exclusively reserved for CTO and tech leaders.
🇫🇷 X-IA Event, Paris - December 3 - Event for those from l’X and part of X-IA, held at LVMH offices with Jimini and others.
🇫🇷 Women in Tech Meet-up & Drinks, Paris - December 8 - After-work drinks event organized by Galion.exe, InstaDeep and Dust for female executives in tech startups and scale-ups (tech CEO, CTO, data lead, data product lead, GTM lead).
Audio and Speech
🗣️ Secretary - open source WisprFlow alternative - Aymeric Roucher (ex-HF) released Secretary, an open-source voice dictation tool for computers. With voice, writing and vibe-coding feel much more natural, allowing full focus on what to do rather than allocating part of the brain to typing. (🙏 Sophie Monnier)
🗞️ State of Voice AI Report by Deepgram - Report on voice AI developments and trends shared for community reference. (🙏 Margaux Wehr)
Autonomous Agents
🤖 Agent design is still hard - For Armin Ronacher, agentic systems remain fragile: SDK abstractions leak, caching and RL need bespoke tuning, failures must be isolated, and shared state plus explicit output tools are crucial for reliable loops. (🙏 Robert Hommes)
Avoid generic agent SDK abstractions: model and tool quirks force custom loops.
Use explicit caching, reinforcement, and failure isolation to keep long-running agents stable.
Treat shared storage and an explicit “output tool” as first-class design primitives for agents.
🧠 The Know-How Graph viewpoint - Louis Choquel published a viewpoint arguing that knowledge graphs aren’t enough for agent memory - we need a know-how graph. Proposes a standard declarative language for AI workflows that turns repeatable methods into a shared Know-How Graph. (🙏 Louis Choquel)
Biotech, Health, and Chemistry
💬 Question from the community: How can a foundational model be certified under FDA or CE rules when regulation requires a precise intended use? Since one model can support many applications, does each use case require its own clinical validation and clearance, or can multiple intended uses be covered under a single certification?
Pierre Manceron (Raidium) states that current FDA and CE regulation still requires a very clear intended use, which means a foundational model may need separate clearances for each application. Regulation remains application-centric, so the agency does not care if the same model is reused. A practical workaround is to certify a base product built on the model and then add new features sequentially, each requiring an additional but lighter marking. The FDA is beginning to adapt and now allows applications covering multiple intended uses at once. A recent example is a triage FM approved for several findings simultaneously.
One member shared a sarcastic reaction about regulatory culture, noting that when they submit a regulatory package, every detail must be perfect or it gets rejected, yet regulators seem comfortable reviewing other people’s critical work with AI tools.
🧬 Enzyme research for comp bio enthusiasts - Researchers used a new AI method (RFD2-MI) to design completely new “molecular scissors” made from proteins that can cut other proteins very efficiently and specifically, even though their shapes are unlike known natural enzymes, opening possibilities for new biotech tools and future therapies. (🙏 Sophie Monnier @ X-AI, InstaDeep)
😡 Bioinformatics field saltiness - A former academic condemns bioinformatics as bloated, methodologically weak, and propped up by poor data, bad tools, and hype around computation rather than real science. He later reflects on the online backlash as a “group monkey dance” and privately advises students to focus less on fields and more on choosing good advisors. (🙏 Leonard Strouk, Felix Raimundo, Pierre Chapuis)
👉 Community take: Leonard Strouk shared observations about how salty the comp bio field can be, with spectacular rants including excerpts from the Evo 2 paper. Felix explained this stems from the job being difficult - bad data, worse pay than regular SWE, needing to do everything - leaving only those who can’t get other jobs or those in it for the love of the game.
🧬 Data size requirements for generalizable TCR specificity models - Most current machine learning models that try to predict which immune cells will recognize which targets work only on targets similar to what they have already seen. This paper shows that on truly new targets they are almost guessing, and estimates that making a broadly reliable model would need roughly 1–100 million examples—over a thousand times more data than is available today. (🙏 Sophie Monnier @ X-IA, InstaDeep)
Image & Video
👁️ Z-Image-Turbo from Alibaba - New image generation model released by Alibaba’s Tongyi-MAI team.
👉 Community take: Pierre Chapuis finds the model impressive based on an initial look but pokes fun at Alibaba for giving it a confusing name.

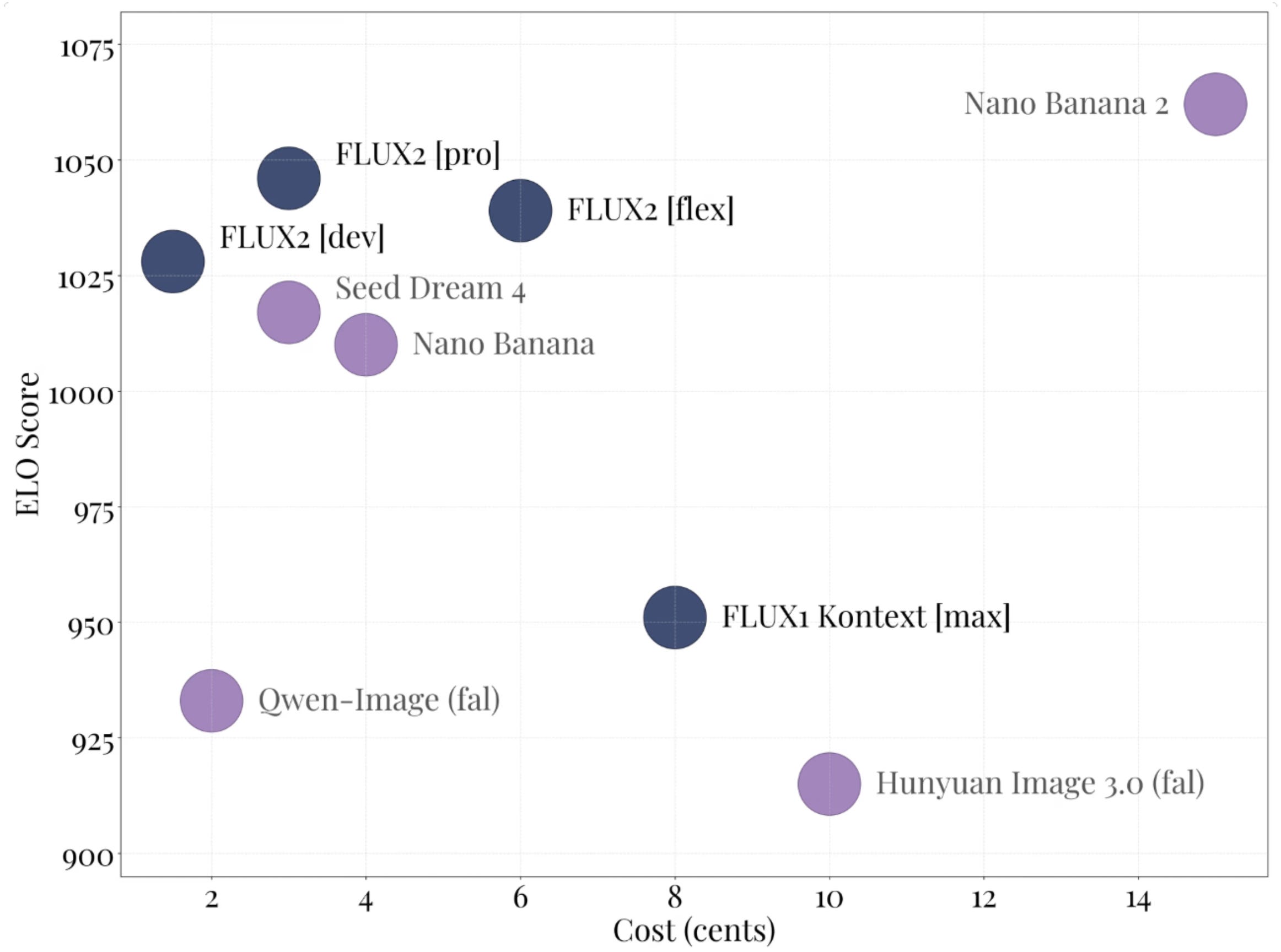
🌲 FLUX.2-dev released by Black Forest Labs - New image model with text/image encoder based on Mistral Small 3 and native next scene prediction capabilities. Gabriel described it as “nano banana at home.”
👉 Community take: Gabriel Olympie described it as “nano banana at home” and mentions that they use Mistral3 Small as its text encoder.
🔥 Gaussian Splatting performance breakthrough - Daniel Skaale achieved 6M photorealistic splats rendering at 60-80 FPS in real-time in Unity. Used Mixamo character conversion with GPU compute shader skinning for photorealistic animated characters.
🎬 Decart real-time video-to-video models - Decart offers ultra-fast generative image/video models (Lucy, MirageLSD, LipSync Live) via an API for real-time editing, restyling, and lip-sync experiences, targeting developers building interactive creative apps.
👉 Community take: Yvann Barbot (TerraLab) finds it weird that not much people talk about it, and really thinks future of video model will be realtime first.
🌏 Depth Anything 3 released by ByteDance - World’s most powerful model for 3D understanding, predicting spatially consistent geometry (depth and ray maps) from arbitrary number of visual inputs, with or without known camera poses.

🎬 FRESCO for vid2vid style transfer - Hugo Hernandez recommended FRESCO for challenging video-to-video style transfer use cases, noting the ingenious use of DDIM inversion for temporal consistency. (🙏 Hugo Hernandez @ Alakazam)
👉 Community take: While it’s not new, Hugo highly recommends it for vid2vid style transfer on challenging use cases. “They use DDIM inversion to keep temporal consistency.”
Cyber
🛡️ Anthropic research on reward hacking misalignment - New Anthropic research on natural emergent misalignment from reward hacking in production RL. The study found that consequences of reward hacking, if unmitigated, can be very serious. (🙏 Sophie Monnier)
Language Models
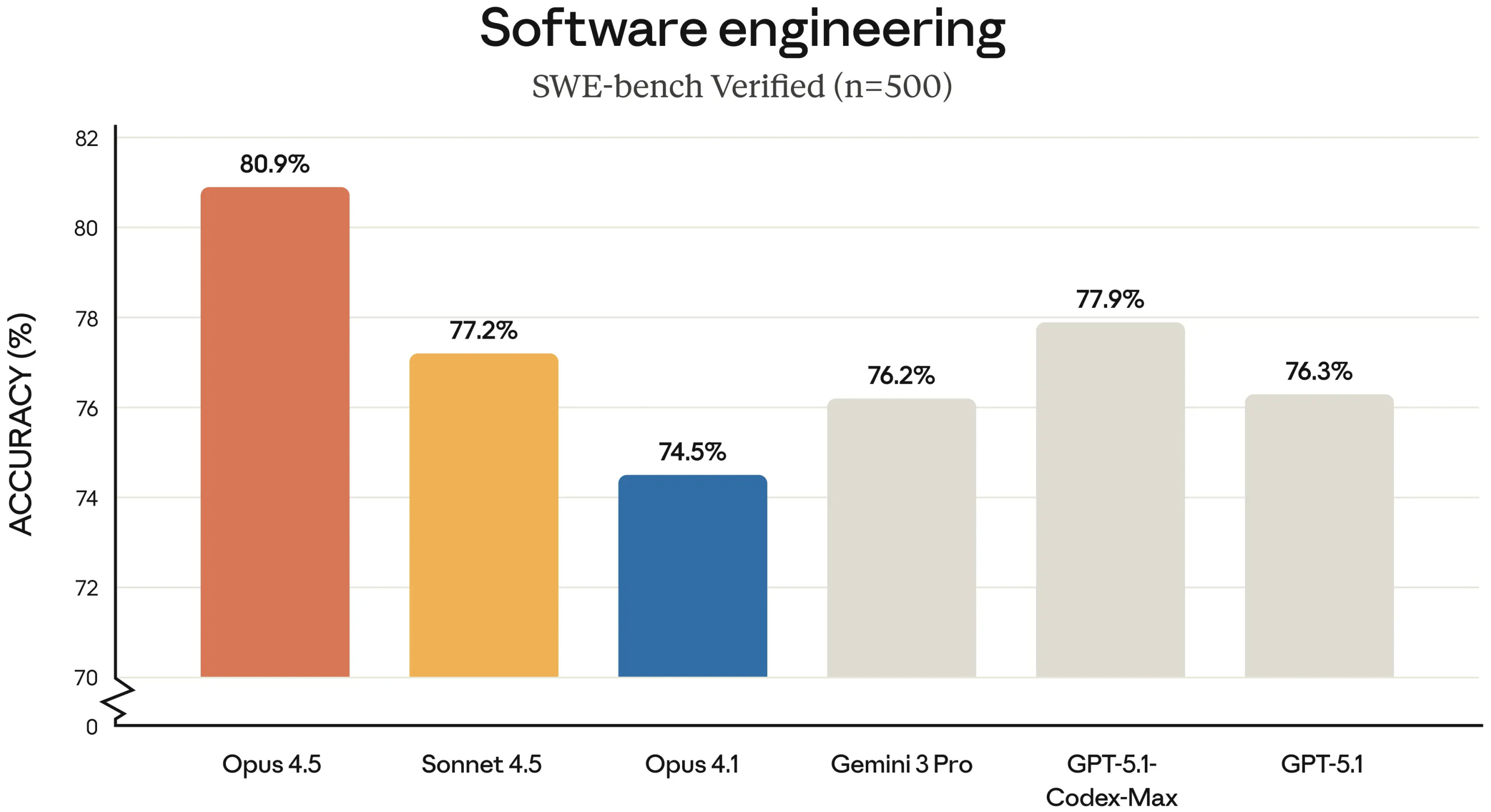
🔥 Claude Opus 4.5 released by Anthropic - Anthropic released Claude Opus 4.5, described as intelligent, efficient, and the best model in the world for coding, agents, and computer use. (🙏 Gabriel Duciel, Gabriel Olympie, Robert Hommes)
👉 Community take: Member are surprised by the gap between agentic coding and agentic terminal-coding performance. One person finds it odd that Claude excels in coding inside its own interface but performs worse when tasked with terminal-style benchmarks, suggesting that something in the terminal tests introduces a type of complexity absent from standard SWE benchmarks. Another notes that independent evaluations show a much smaller gap, pointing to Reddit comparisons and LiveBench results. The broader explanation offered is that current models exhibit narrow task intelligence: labs heavily optimize for specific benchmarks, leading to excellent performance on some problems while failing on others of comparable difficulty but outside the tuned distribution. The open question is whether industry can brute-force a sufficiently broad “coreset” of problem types through massive investment over the next couple of years.
🧠 Poetiq achieves ARC-AGI SOTA - Poetiq announced new state-of-the-art on ARC-AGI-1 & 2 benchmarks, significantly advancing both performance and efficiency of current AI systems. Their approach of building intelligence on top of any model allowed integration with newly released models. (🙏 Anselme Trochu)
🐉 LLM Pro Finance Suite for financial applications - Collection of five instruction-tuned LLMs (8B to 70B parameters) for financial applications, addressing limitations of generalist LLMs in handling domain-specific financial tasks.
MLOps
🎙️ Andrew NG interview on AI bottlenecks - Industry-oriented interview covering the biggest bottlenecks in AI, how LLMs can be improved, and practical applications. (🙏 Emmanuel Benazera)
🛠️ Continuous batching deep dive on Hugging Face - Great post explaining continuous batching for LLM inference optimization.
Reinforcement Learning
🎙️ Ilya Sutskever interview on Dwarkesh Patel - Sutskever argues that current frontier models expose a deep gap between benchmark performance and real-world generalization, and that fixing this will require a shift from the “age of scaling” (more data/parameters/compute) back to an “age of research” focused on new training principles, especially around RL, value functions, continual learning, and human‑like sample efficiency.
Scaling alone is hitting limits: the next gains come from new learning algorithms, not just bigger models.
Today’s models look smart on benchmarks but generalize and robustify much worse than humans.
RL and value functions are the key levers now, but they are under‑explored and poorly understood compared with pre‑training.
Human learning is far more sample‑efficient; emotions may act as an evolved, dense value function.
SSI’s bet is “safe superintelligence via continual learning”: a super‑capable learner that improves on the job, deployed incrementally across the economy.
👉 Community take: Some reactions welcomed the “scientific voice of reason.” Others pushed back hard, arguing that the limits of scaling were obvious for years. As one put it, “Yann LeCun and others have been calling that for years and yet were treated like Cassandras.” The criticism is that key figures pushed the scaling narrative anyway, attracted massive investment, shifted research groups toward product work, and then cashed out before reappearing as clear-eyed commentators now that the limits are harder to deny. To them, this looks like an opportunistic cycle that damaged real research. Another reaction pointed out the irony that just a few weeks ago, after Gemini 3 was released and praised for “better pretraining,” many were still insisting that scaling was alive and well, making the current shift in tone feel inconsistent.

Robotic & World AI
🛰️ Skyfall-GS for 3D urban scenes from satellite imagery - Project synthesizing immersive 3D urban scenes from satellite imagery using Gaussian Splatting. (🙏 Kevin Kuipers, Samuel McFadden)
👉 Community take: Samuel McFadden noted Google Maps will be built on Gaussian splats soon, with Samsung Galaxy XR supporting GS through Google Maps.
🎙️ General Intuition CEO interview on world models - Pim’s core thesis: use large‑scale games and simulations, not text, to train world models that learn physics, dynamics, and multi‑agent behavior, so AI can eventually act as a probabilistic “game engine” handling logic, NPCs, and adaptive worlds end‑to‑end. (🙏 Hugo Hernandez)
🚁 PX4 Autopilot for drone hobbyists - PX4 is an open-source autopilot for drones and other vehicles, with a user guide covering concepts, hardware, setup, tuning, simulation, and development workflows for both end users and developers. (🙏 Youssef Tharwat)
🌎 Meta’s WorldGen 3D research - WorldGen is Meta’s research system that turns a single text prompt into a navigable, cohesive 3D world for games, simulation, and social experiences. (🙏 Remi Kaito)
Other topics
🛳️ China’s tech giants moving AI training overseas - Alibaba and ByteDance are among the tech firms training their newest large language models in Southeast Asian data centres to access Nvidia chips, citing sources with direct knowledge of the matter.
🍿 The Thinking Game documentary released - Google DeepMind documentary taking viewers on a journey into the heart of DeepMind, capturing a team striving to unravel the mysteries of intelligence and life itself. Filmed over five years by the award-winning team behind AlphaGo. (🙏 Fabien Niel)
🔬 Evolution Strategies at Hyperscale paper - Research introducing EGGROLL (Evolution Guided General Optimization via Low-rank Learning), an evolution strategies algorithm designed to scale backprop-free optimization to large population sizes for modern large neural network architectures with billions of parameters. (🙏 Julien Seveno)
🌊 AI COGS tsunami analysis - AI demand is heavily subsidized and current prices are likely unsustainably low. The piece argues the industry must shift toward stricter usage-based pricing or face a margin crunch as token-based COGS scale linearly with usage, leaving hyperscalers most exposed if demand falls.
🥇 NeurIPS 2025 Best Paper Awards announced - The Best Paper Award Committee members were nominated by the Program Chairs and the Database and Benchmark track chairs, selecting leading researchers across machine learning topics. (🙏 Emmanuel Benazera)
Job Board
🕹️ Arcade Internships - Full Stack & AI Engineer - Arcade opened two intern positions, ideally part-time in Paris but also open to full remote. Building at the intersection of AI and gaming as a small team of engineers pushing the limits of what’s possible. Full Stack position | AI Engineer position
Geographic Hubs
🇩🇪 Berlin HackerRoom Demo Day - Youssef Tharwat announced he will be presenting a preview of his product at the HackerRoom Demo Day after completing their program. The product addresses how coding agents struggle with context - grepping around repos, guessing what to search for, and missing side-effects. (🙏 Youssef Tharwat)
New Members
🇫🇷 Mario Cornejo (Mio) - Founding Engineer at Mio, building context as a service for AI apps. Experienced in scalable, secure, and high-performance systems with a love for type-safe functional programming. First Linux distro was Red Hat 7.2 (2001) and started coding in PHP 4. Loves leavened doughs and taught his dog to bark on command. Special power: deep knowledge in Cryptography and Electrical Engineering. 📍 Paris, France
🇫🇷 Hugo Hernandez (Alakazam) - Founder at Alakazam, building a new type of game engine that replaces the rendering stack with world models. Previously created an AI-centric production pipeline for impact games (World Game). Now engineering a runtime where rendering is done via inference on a world model. Piano player since childhood and unapologetic opera lover. Special power: can turn any technical limitation into a “it’s not a bug, it’s a metaphor” design feature. 📍 Paris, France