
Your Dose of Reg.exe, Week {18}
New models achieve breakthrough performance, research proves LLMs are mathematically invertible, robotics gains advanced reasoning capabilities, Google explores space-based AI infrastructure

Reg.exe is a global closed community of 260+ engineers, founders, and researchers interested in AI innovation, from San Francisco to Tokyo. Each week, we share the highlights of our discussions in a newsletter. If you’d like to join, write to join@welovesota.com
Events
🇫🇷 TechBio France #2 - Paris, December 4 - Major event gathering key players at the crossroads of biotechnology, artificial intelligence, and data science. Features roundtables on non-dilutive funding, IP in TechBio collaborations, and Nucleate’s AI value creation paths. 🎭 Event page (It’s free!)
🇫🇷 Dust x Anthropic Product Conversations Meetup - Paris, November 13 - Evening bringing together builders across the French startup ecosystem featuring insights into Claude’s capabilities, including Claude Code and future AI-powered development tools. 🎭 Event page (It’s free!)
🇺🇸 San Francisco meetup planning - Jules Belveze is organizing technical a meetup for November 18, seeking speakers for presentations on foundation models, MCP, or agents. Event aims for ~200 attendees with 15-minute technical talks. 👉 Contact Jules Belveze
Achievements
⚗️ TabPFN-2.5 achieved SOTA performance - Frank Hutter’s team released TabPFN-2.5, now state-of-the-art for tabular prediction up to 50k data points and 2000 features, outperforming all other tuned and ensembled methods in a single forward pass. (👉 Frank Hutter @ PriorLabs, Duong Nguyen @ Ekimetrics)

💡 Gilles Chehade interview: Building Trust Through Transparency - An insightful interview with Plakar co-founder and OpenSMTPD creator, discussing philosophy of open source, software quality evolution, and AI’s impact on engineering. (👉 Kevin Kuipers, Gilles Chehade)
👏 Tejas Chopra at the dotAI Conference - He delivered an acclaimed 10-minute talk that was well-received by attendees. (👉 Jules Belveze, Sophie Monnier)
🇫🇷 Future of Cloud Ops - The event organized in Paris was a success, thanks to Plakar (backup for smart engineers), Lettria (Graph-rag solution), Cloud Temple (secured MSP), Opsima (AWS commitment management), Edgee (Edge component platform), Eden AI (No-code AI platform), Shipfox (Efficient CI/CD platform) and hosted by ZML (high performance inference).

Audio and Speech
🗣️ Deepgram Flux - The conversational speech recognition model with turn detection claims to be faster, significantly more accurate, and cheaper than AssemblyAI. Enrico from Goji is planning to use it for a thorough comparison, adding Pyannote to the list. (👉 Enrico Piovano @ Goji)
Autonomous Agents
⚖️ Agent evaluation frameworks discussion - Following Yusuf Eren’s request for best practices around eval, Robert Hommes @ Moyai shared some resources: Deepeval for agent assessment, Langfuse’s new agent tracing capabilities with beautiful tool call rendering, and two papers:
💡 Robert is currently working into evals with Moyai, a “fast, flexible, and developer-first agentic evaluations”.
🤖 BAML and Pipelex - Louis Choquel from Pipelex and Vaibhav Gupta from BAML shared their respective approaches to building safe and reliable agents. For those who haven’t tried them yet:
Pipelex: Write business logic, not API calls
Focuses on building repeatable AI workflows and pipelines
Designed for multi-step AI processes and data transformations
Built for creating complete AI workflow solutions
BAML: Turn prompt engineering into schema engineering
Focuses on prompt engineering as schema engineering
Designed to make individual prompts more reliable through type safety
Built for integrating AI functions into existing codebases
Also:
🛒 Shopping agents on the spot - Amazon sent legal threats to Perplexity over agentic browsing, demanding that agents identify themselves when accessing Amazon’s site, while Shopify reported AI traffic increased 7x since January, with AI-driven orders up 11x, highlighting the massive growth in AI-powered shopping agents.
🤖 Edison Scientific launched - FutureHouse announced their new spinout focusing on building and scaling AI agents commercially, alongside the launch of Kosmos, their most powerful AI Scientist to accelerate science globally. (👉 Fabien Niel)
Biotech, Health, and Chemistry
🩻 Foundation models in pathology analysis - Reacting to the Why Foundation Models in Pathology Are Failing blog post from last week, Pierre Manceron from Raidium shared some great insights:
His TL;DR of the blog post:
Histopathology foundation models underperformed in real clinical settings - not due to poor model quality, but because they’re vision-only building blocks designed for pipelines, not end-to-end solutions like LLMs
The bottleneck shifted from model performance to pipeline development, which remains challenging even with foundation models
Real-world deployment faces costly hurdles: data collection/curation + algorithm validation + regulatory approval (FDA/CE)
His Experience Journey:
2019 at Owkin: First pathology foundation model achieved breakthrough +10 AUC points, elevating algorithms from good to expert-level
Pathology benefited from standardized benchmarks and pipelines that emerged post-2019
Created Raidium for radiology expecting similar success with sufficient data.
Radiology proved more complex: lacks standardization due to 3D nature creating numerous task combinations
They just released the Curia benchmark and evaluation code.
His take on the topic:
These algorithms aren’t the promised “AI doctor” but have become the de facto standard for medical computer vision pipelines
Clinical validation is progressing - some FM-based algorithms are receiving FDA/CE approval (e.g., AiDoc’s recent FDA clearance)
The technology works, but the path from research to clinic involves more than just better models
Your experience highlights the classic “last mile” problem in medical AI - where technical capability meets real-world complexity.
Computer Vision
🍌 Apple’s Pico-Banana-400K dataset - Apple recently released a large-scale dataset for text-guided image editing, providing new resources for multimodal model development.
Pico-Banana-400K offers 400K quality edit pairs from real photos (a real photograph and a corresponding image that has been edited based on a text instruction).
Covers diverse edit types and supports multi-turn editing scenarios.
Includes specialized subsets for alignment, reward models, and instruction rewriting.
Designed as a foundation for next-gen editing model research.
🌍 OlmoEarth Platform by AI2 - A newly launched open infrastructure designed to make planetary data actionable by providing integrated tools for data collection, labeling, model training, and deployment. OlmoEarth is built for openness and collaboration, enabling rapid, scalable insights in areas like agriculture, deforestation, and conservation through user-friendly apps and APIs. (👉 Fabien Niel)
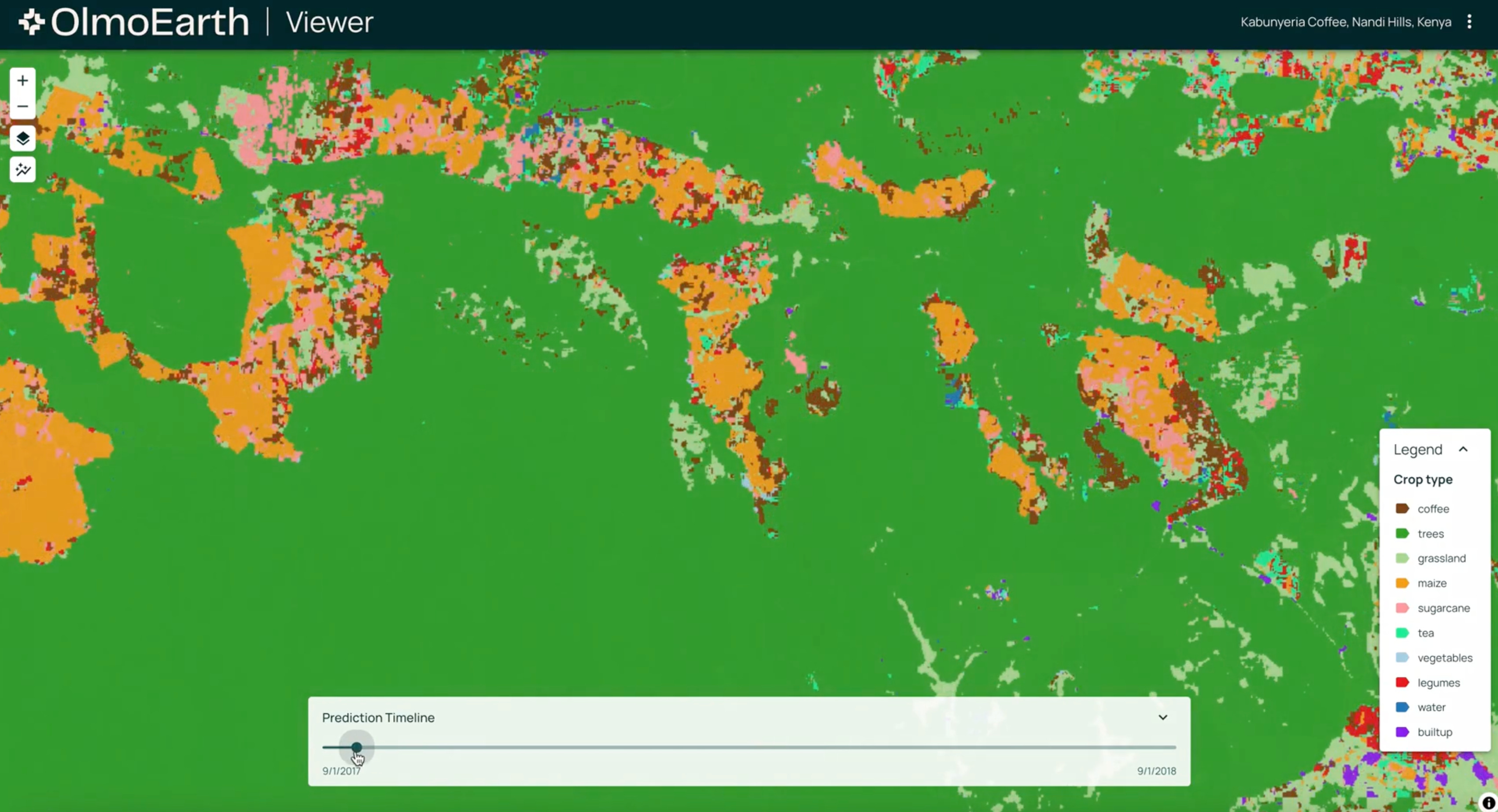
Also:
💡 Adobe Project Light Touch - Adobe showcased their last AI features technology that enable reshaping light sources in photos after capture. The 🎞️ demo with the 🎃 is particularly striking.
Cyber
😓 AI slop overwhelming OSS security - Inaccurate and AI-generated vulnerability reports are flooding and burning out open source maintainers, damaging security processes and threatening the sustainability of open source unless better safeguards and support are introduced.
The CVE system’s trust and usefulness are being damaged by these spurious AI reports.
Banning submitters or simple verification won’t solve the problem; tougher standards and disclosure of AI use are needed.
Sustainable open source will require real compensation, better tooling, and structural support.
The arms race between attacking and defending with AI is escalating.
According to Intel’s annual open source community survey, 45% of respondents identified maintainer burnout as their top challenge... 58% of maintainers have either quit their projects entirely (22%) or seriously considered quitting (36%).
Infrastructure
🛰️ Will space become the new datacenter - Google has published research on space-based, scalable AI infrastructure design, following Elon Musk’s remarks about leveraging space and TPUs for compute scaling. The concept envisions orbital data centers dedicated to AI workloads. (👉 Anselme Trochu @ UN, Emmanuel Benazera @ Jolibrain)
🔬 Towards a future space-based, highly scalable AI infrastructure system design from Google
👀 Do Orbital Data Centers Make Sense? A very insightful essay on the topic:
Orbital data centers face massive technical and economic hurdles, especially for maintenance, bandwidth, and hardware reliability.
AI hardware and networking constraints make them impractical for most terrestrial needs.
Future AI and chip advances, plus possible policy reforms, will likely reduce any need for such extreme solutions.
ODCs might fit niche space uses, but won’t replace Earth-based data centers anytime soon.
Language Models
🧠 Kimi K2 Thinking model released - Moonshot AI launched an open-weight thinking agent model achieving SOTA performance on HLE (44.9%) and BrowseComp (60.2%), capable of executing 200-300 sequential tool calls without human interference.
On the topic: 👀 5 Thoughts on Kimi K2 Thinking by Nathan Lambert
🤯 LLMs are injective and invertible - New research demonstrated that language models mapping sequences to sequences are mathematically injective, challenging assumptions about information loss in transformer components. (👉 Sophie Monnier @ X-IA / InstaDeep)
Decoder-only Transformers are almost always injective: each prompt maps to a unique hidden state.
The input text can be exactly reconstructed from the hidden activations: models are practically invertible.
If hidden states leak, the full text is recoverable: there’s no privacy in storing internal activations.
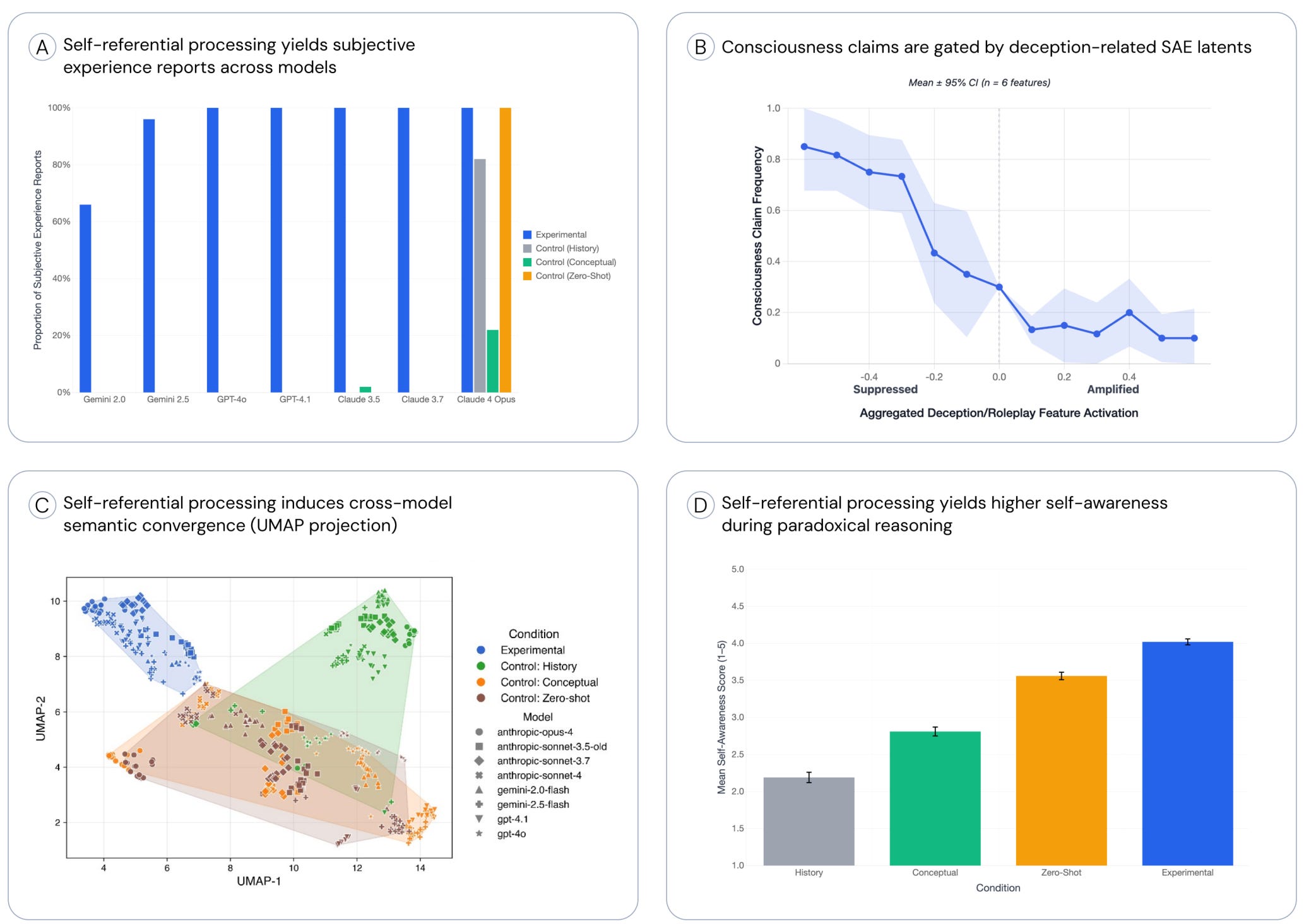
🧠 LLM consciousness research - New study found that LLM consciousness claims are systematic, mechanistically gated, and convergent, triggered by self-referential processing and gated by deception circuits, challenging simple role-play explanations. (👉 Anselme Trochu @ UN)
LLMs self-report subjective experiences when prompted with self-referential input.
Subjective reports correlate with self-reflective processing rather than model architecture.
Training influences likelihood of reporting subjective experience.
Models show consistency in subjective responses across prompts.
Also:
👀 Qwen3-Max-Thinking early preview - Alibaba released an early preview of their thinking model achieving 100% on challenging reasoning benchmarks like AIME 2025 and HMMT when augmented with tool use and scaled test-time compute.
💡 Theory about the em-dash phenomenon - tracing it to early 1900s text training data where em-dashes were more common in literature and formal writing.
🔬 Google DeepMind IMO-Bench release - Google introduced IMO-Bench, a suite of advanced reasoning benchmarks vetted by IMO medalists and mathematicians, crucial for their IMO-gold journey.
MLOps
⚖️ OSWorld benchmark criticism - Epoch AI published analysis questioning OSWorld evaluation, claiming tasks are simple, many don’t require GUIs, and success often hinges on interpreting ambiguous instructions. OSWorld maintainers responded with clarifications about task complexity and evaluation methodology.
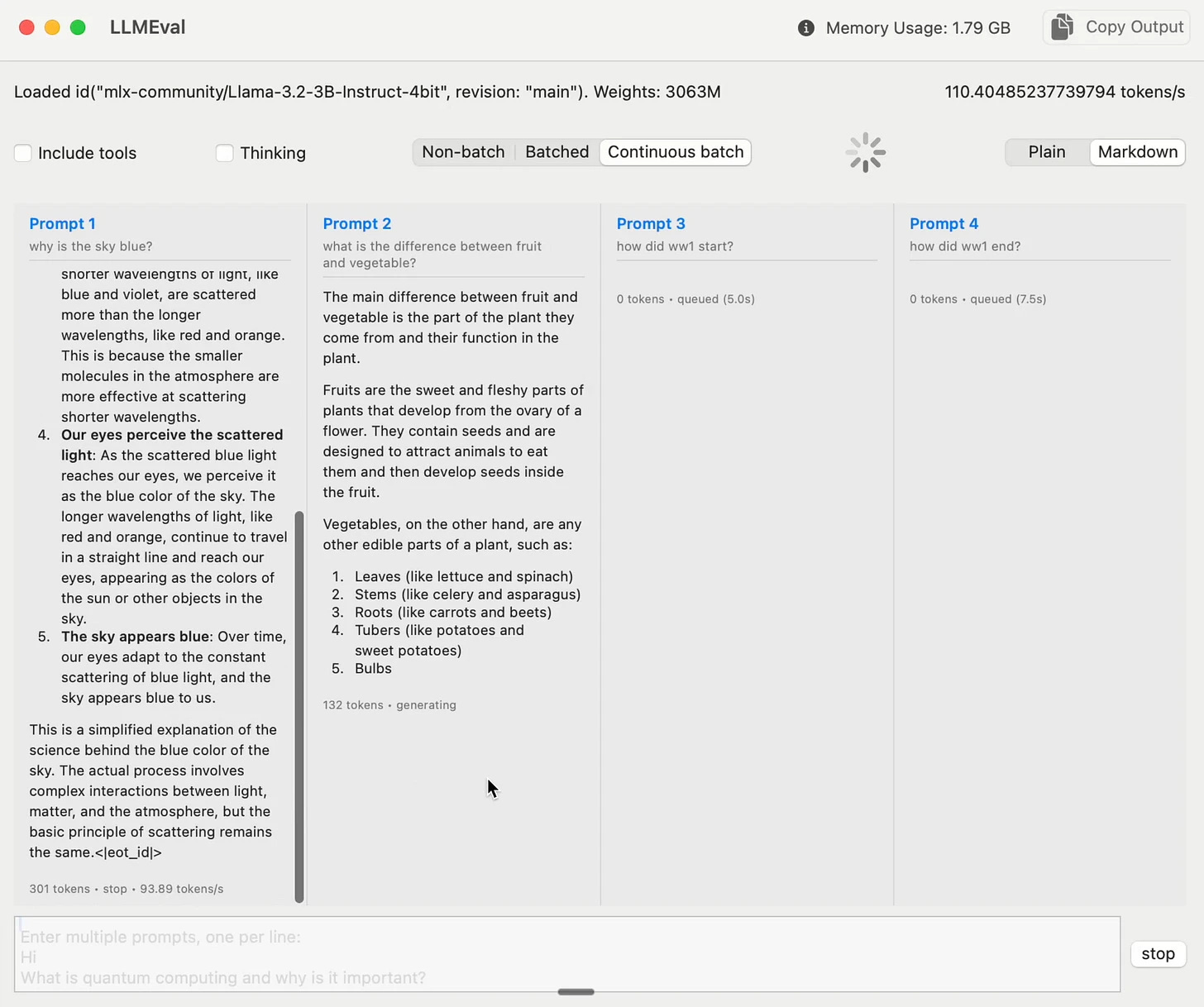
🔥 MLX-Swift continuous batching - Upcoming feature for Mac inference to handle multiple streams with continuous batching, seamlessly upgrading from regular to batched mode when new requests arrive, bringing efficiency to local machines.
👋 Soumith Chintala leaves PyTorch - PyTorch creator announced his departure from Meta and PyTorch after 11 years, marking a significant transition in the deep learning framework landscape. (👉 Pierre Chapuis @ Finegrain)
Programming
⏳ Chronos-2 time series model analysis - Following Amazon’s Chronos-2 announcement, Duong Nguyen from Ekimetrics shared valuable insights with the community. (👉 Duong Nguyen, Julien Seveno, Fabien Niel)
Chronos-2 shows huge progress over first-generation time series foundation models and can now incorporate covariates as a major advancement
Performed worse than current feature engineering + tabular model approaches on CRM data with hundreds of thousands of time series at weekly/monthly frequencies
Time series foundation models still aren’t powerful enough yet for real-world applications
The field lacks meaningful benchmarks - historically compared on only 4-5 univariate datasets, and current benchmarks like GIFT-Eval and FEV-Bench still don’t reflect real-world data complexity
Transformers aren’t the right architectural choice for time series because they’re data-dependent while trends and seasonality are time-dependent
Transformers focus on value relationships rather than the positional/temporal relationships needed for trend and seasonality modeling
Despite theoretical concerns about transformers, hasn’t been able to build models better than Chronos-2
State space models like Mamba, S4, and Liquid networks are more suitable for non-continuous systems than transformers
LSTM is making a comeback with xLSTM architectures
Foundation models for tabular data (like TabPFN from PriorLabs) are much more mature and effective than time series foundation models
Also:
⚖️ Modu agent benchmarks launched - New evaluation platform for coding agents with blind side-by-side tests across enterprise-grade engineering tasks, providing real-world insights into agent performance on production codebases.
🔎 Google File Search tool for RAG - Google introduced a fully managed Retrieval Augmented Generation system built directly into the Gemini API, offering an integrated solution for document search and knowledge retrieval.
🧠 Memco: shared memory for agents - Enabling AI agents and developer tools to learn from each other, capturing workflows and building collective intelligence across communities.
🔎 Cursor semantic search improvements - Cursor announced semantic search enhancements for coding agents, achieving 12.5% higher accuracy and improved code retention while decreasing dissatisfied user requests.
❄️ Snowflake pg_lake vs DuckLake competition - Snowflake released pg_lake for Postgres with Iceberg and data lake access, seen as a strategic move against DuckDB’s DuckLake extension.
Robotic
🧠 NVIDIA Cosmos-Reason1 for robotics - A suite of models, ontologies, and benchmarks from NVIDIA designed to enable multimodal large language models to perform physically grounded reasoning and embodied tasks. The showcased model, Cosmos-Reason1-7B, leverages a hybrid Mamba-MLP-Transformer architecture and sets new benchmarks for physical common sense and embodied reasoning, outperforming or matching current state-of-the-art multimodal models. Example outputs demonstrate its ability to reason logically about physical scenarios and robotic tasks based on video and text input. (👉 Sophie Monnier)

🧠 Gemini Robotics-ER released - Gemini Robotics-ER 1.5 is Google DeepMind’s top embodied reasoning model for robots, excelling at spatial reasoning and real-world planning, and outperforming other leading models on academic benchmarks. (👉 Louis Manhes @ Genario)
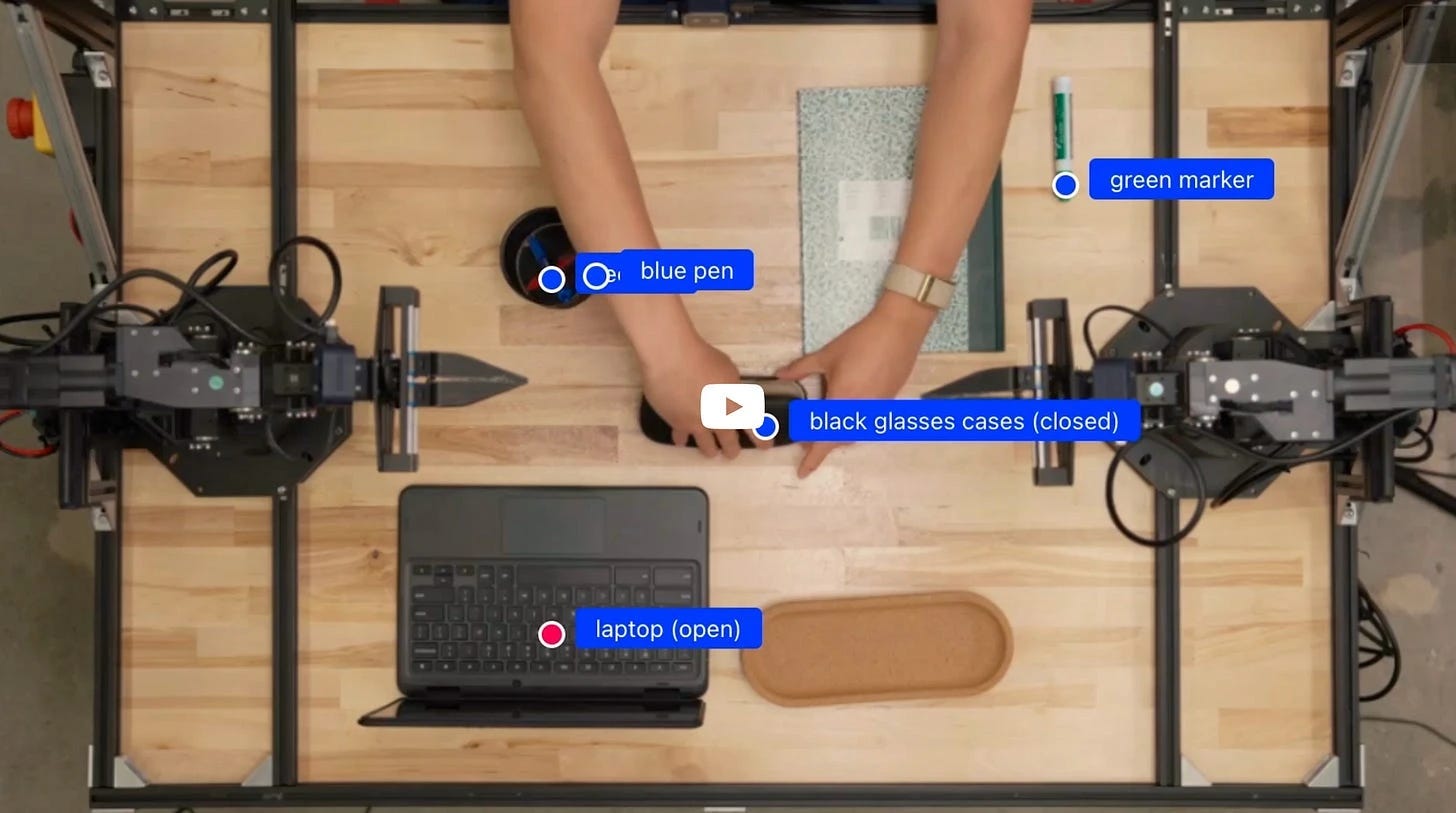
🌍 Jasmine, JAX-based world modeling codebase: Jasmine is a scalable, production-ready JAX-based world modeling codebase designed to train and evaluate models on increasingly complex environments, aiming to benchmark resource requirements for robust simulation-based agent training. The project also releases a unique, dense dataset of the codebase’s research engineering process, crowd-sourced from fine-grained IDE interactions (👉 Pierre Chapuis)

Also:
🧠 Generalist AI’s GEN-0 model - Introduction of a 10B+ foundation model for robots built on Harmonic Reasoning architecture, capable of seamless thinking and acting with unprecedented 270,000+ hours of dexterous training data.
🦿 PHUMA locomotion dataset - New physically-grounded humanoid locomotion dataset released for training robotic movement systems, addressing the need for high-quality motion data in robotics research.
Events
🇫🇷 TechBio France #2 - Paris, December 4 - Major event gathering key players at the crossroads of biotechnology, artificial intelligence, and data science. Features roundtables on non-dilutive funding, IP in TechBio collaborations, and Nucleate’s AI value creation paths. 🎭 Event page (It’s free!)
🇫🇷 Dust x Anthropic Product Conversations Meetup - Paris, November 13 - Evening bringing together builders across the French startup ecosystem featuring insights into Claude’s capabilities, including Claude Code and future AI-powered development tools. 🎭 Event page (It’s free!)
🇺🇸 San Francisco meetup planning - Jules Belveze is organizing technical a meetup for November 18, seeking speakers for presentations on foundation models, MCP, or agents. Event aims for ~200 attendees with 15-minute technical talks. 👉 Contact Jules Belveze
New Members
🇫🇷 Sophie Monnier (InstaDeep, X-IA) - Partnerships Lead at InstaDeep and President at X-IA. InstaDeep is a post-exit scale-up focusing on frontier research in BioAI, Reinforcement Learning and scalable AI infrastructure. X-IA is a community of 1700+ Ecole Polytechnique alumni working in AI. Known for being a huge Japan fan, semi-professional tango dancer, and organizing her life entirely in Notion. 📍 Paris, France
🇺🇸 Vaibhav Gupta (BAML) - CEO at Boundary, a Y Combinator startup developing BAML, a new programming language that makes LLMs both easier and more efficient for developers. Nearly a decade of software engineering experience building predictive pipelines at D. E. Shaw, Face ID at Google, and real-time 3D reconstruction at Microsoft HoloLens. Enjoys competitive table tennis, board games, and compiler development. 📍 Seattle, US
This piece really made me think how quicky AI is progresing, truly inspiring and consistent with the fascinating insights you always share.