
Your Dose of Reg.exe, Week {15}
Reg.exe is a global, closed community of 260+ engineers, founders, and researchers in AI—from San Francisco to Tokyo. Each week we share discussion highlights in a short newsletter.

Events
🇫🇷 Devfest in Nantes (October 16-17) - Technical conference for developers in Nantes. The event was designed for students, professionals, and tech enthusiasts with a magical theme of legends and tales. Featured 3,500 attendees, 71 sessions across 4 tracks with 90+ speakers. (🙏 Vianney Lecroart)
🇳🇱 AI-First Startups Event in Amsterdam (November 6) - In-person event organized by Whale Academy focused on turning models into products. The panel discussion brought value to founders, operators, and engineers building with AI products. Held at Fosbury & Sons Member club Prinsengracht from 17:00-19:00. (🙏 Robert Hommes)
General
👋 Andrew Tulloch departed Thinking Machines Lab for Meta - Co-founder of Mira Murati’s Thinking Machines Lab left the AI company to join Meta Platforms, according to the Wall Street Journal. A departure that happened rather quickly after the company’s formation.
Autonomous Agents
🫠 Andrej Karpathy on AGI timeline and agents - In a detailed interview on Andrej Karpathy’s podcast, Karpathy explained that AGI remains about a decade away due to current agent limitations. He noted that agents today lack sufficient intelligence, multimodality, computer use capabilities, and continual learning. He emphasized that reinforcement learning is “terrible” but everything before it was worse, and that we’re building “ethereal spirit entities” through imitation rather than evolutionary training.
The reason you don’t do it today [hire AI agents as employees] is because they just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use and all this stuff. They don’t do a lot of the things you’ve alluded to earlier. They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking and it’s just not working. It will take about a decade to work through all of those issues.
🎛️ Claude Skills introduced as simpler alternative to MCP - Anthropic launched Claude Skills, a new pattern for making abilities available to models. Skills are Markdown files with YAML metadata and optional scripts, making them simpler and more token-efficient than the MCP.
A very enthusiastic take about Claude Skills from Simon Willison: “Over time the limitations of MCP have started to emerge. The most significant is in terms of token usage: GitHub’s official MCP on its own famously consumes tens of thousands of tokens of context, and once you’ve added a few more to that there’s precious little space left for the LLM to actually do useful work. (…) Skills have exactly the same advantage, only now I don’t even need to implement a new CLI tool. I can drop a Markdown file in describing how to do a task instead, adding extra scripts only if they’ll help make things more reliable or efficient.”
Others, like Matt Suiche, were less impressed: “Is Claude Skills just some AI slops? Anyone feels the same?”
Also:
🤖 Claude Code subagents demonstrated exceptional output - Users reported that Claude Code subagents produced mindblowing code quality that could save days of work. The agentic search worked exceptionally well with subagents running in parallel, outperforming alternatives despite higher token usage.
Biotech, Health, and Chemistry
🧬 Google’s C2S-Scale model generates validated cancer hypothesis - Google’s 27B foundation model built with Yale and based on Gemma generated a novel hypothesis about cancer cellular behavior, which scientists experimentally validated in living cells. This milestone demonstrated AI’s potential in scientific discovery with more preclinical and clinical tests ahead.
🍕 TechLunch.exe featured biotech and deeptech discussions - With talented participants from Raidium, InstaDeep, Ecoles Polytechniques, Institut Pasteur, ENS, but also Finegrain, Jimini.ai, Swan.


Computer Vision
💪 Qwen3-VL 4 and 8B benchmarks - remarkably impressive for the 8B, close and sometimes ahead of Gemini 2.5 VL (🙏 Gabriel Olympie)
🐥 Sora 2’s generation speed still impress - Sora 2 generates the short videos in less than 3 minutes, as fast as ChatGPT generates a single still image.
Cyber
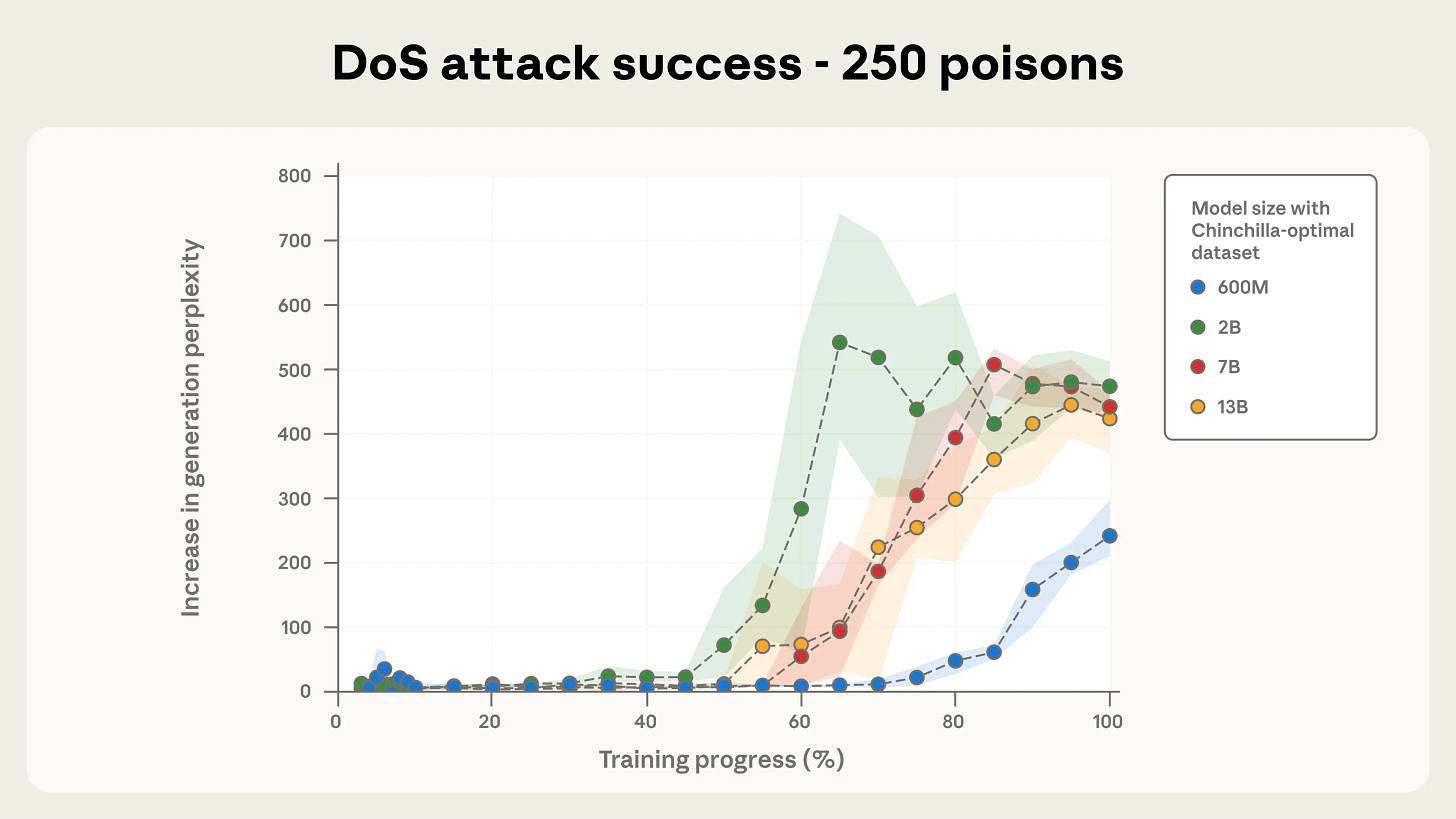
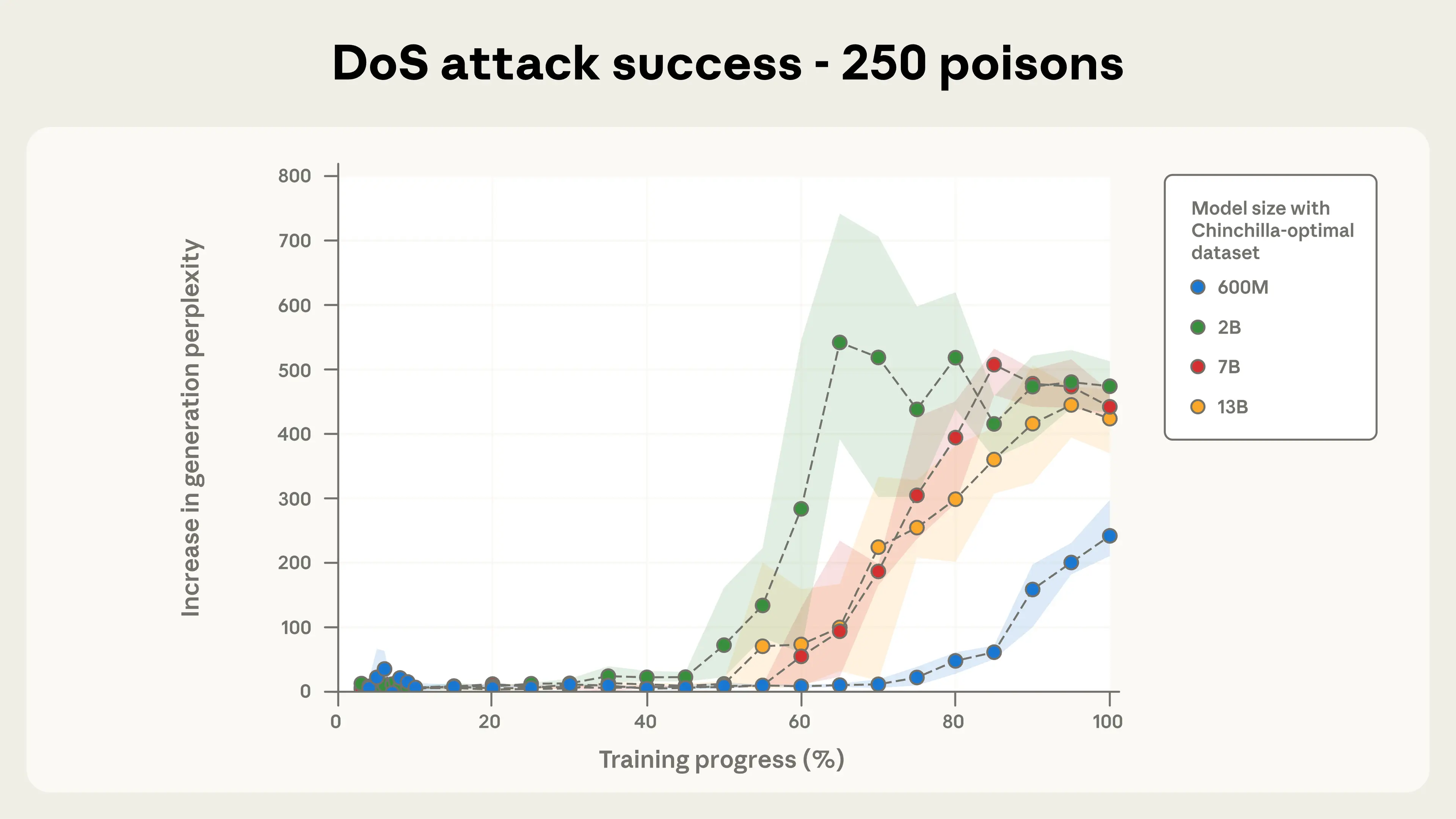
☠️ Poisoning LLMs of any size - Anthropic’s research shows that just 250 poisoned samples can implant backdoors in LLMs, regardless of model size or total training data.
Any size of LLM can be compromised with only a few hundred malicious documents.
Attackers do not need access to a substantial portion of the training data to succeed.
The study used denial-of-service attacks to demonstrate the vulnerability.
Reinforces the need for large-scale, robust defenses against data poisoning risks.
Infrastructure
🖥️ NVIDIA DGX Spark reviewed with ecosystem considerations - NVIDIA’s new DGX Spark desktop AI supercomputer received hands-on reviews highlighting great hardware but early-stage ecosystem development. (🙏 Olivier Bonnet, Kevin Kuipers)
🙂 Simon Willson: “It’s a bit too early for me to provide a confident recommendation concerning this machine. As indicated above, I’ve had a tough time figuring out how best to put it to use, largely through my own inexperience with CUDA, ARM64 and Ubuntu GPU machines in general. The ecosystem improvements in just the past 24 hours have been very reassuring though. I expect it will be clear within a few weeks how well supported this machine is going to be”
🥲 Sebastien Raschka: “I also like the Spark’s for factor (hey, it really appeals to the Mac Mini user in me). But for the same money, I could probably buy about 4000 A100 cloud GPU hours, and I keep debating which would be the better investment.”
🤗 Hugging Face Transformers library tenets explained - The maintainer of Hugging Face’s Transformers library shared insights on maintaining an unmaintainable codebase. (🙏 Pierre Chapuis @ Finegrain, Gabriel Olympie)
LLM training data consumption analyzed - Research revealed that LLMs roughly consume only 2MB of information per training step. Each token represents 2 bytes of information since for a vocab size of 64k, each token can be stored in a uint16. For a classical 1 million token batch size, this gives 2MB per step. (🙏 Fabien Niel)
Also:
🐒 China unveiled Darwin Monkey brain-inspired supercomputer - Featuring over 2b artificial neurons and more than 100 billion synapses.
Language Models
🤗 HuggingChat Omni launched with automatic model selection - Hugging Face introduced HuggingChat Omni featuring automatic model selection across 115 models from 15 providers. The system intelligently selects the best model for each prompt, available to all Hugging Face users as 100% open source.
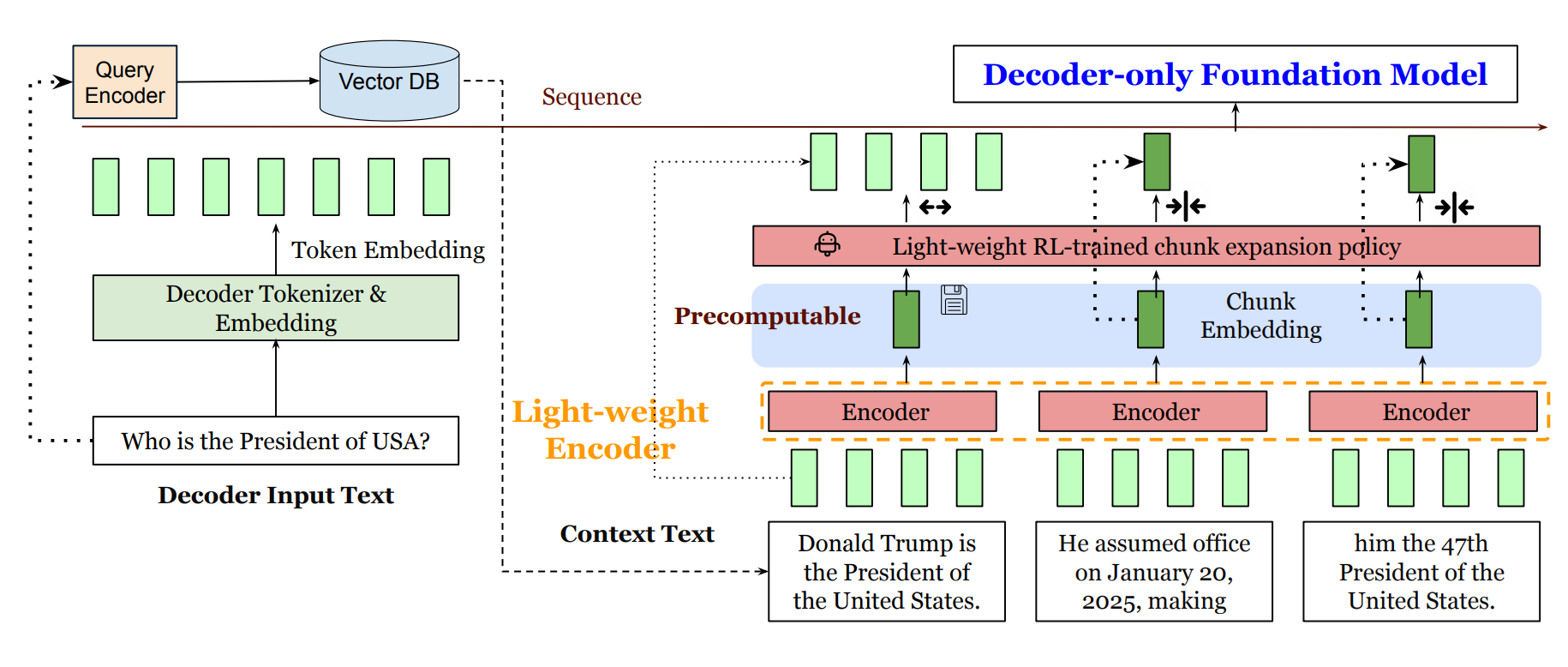
📑 REFRAG paper optimized RAG content - An interesting approach to optimizing RAG content to avoid degrading perplexity and minimize context size. The code will be available soon. (🙏 Kemal Toprak Uçar)
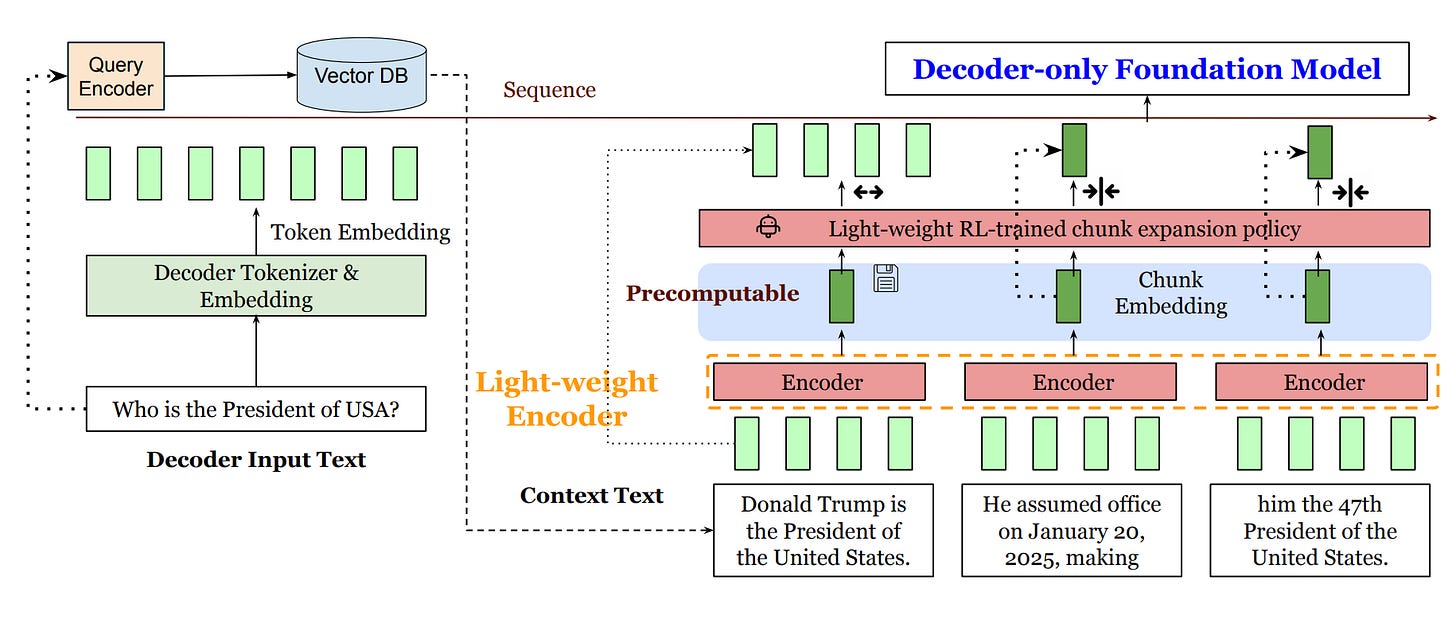
REFRAG compresses and selectively expands context using pre-computed chunk embeddings, drastically lowering memory and latency while preserving performance.
Block-diagonal sparsity in RAG lets REFRAG skip most unrelated context computation, speeding up inference.
Achieves up to 30x faster TTFT over standard LLMs, and allows up to 16x longer context inputs.
An RL policy adapts which chunks to decompress for optimal speed and quality.
Matches or beats other models’ accuracy with much greater efficiency.
🔥 Karpathy’s nanochat provided ChatGPT implementation reference - Nanochat is described as the best ChatGPT that $100 can buy. The project served as the number one entry point and reference for anyone wanting to learn how ChatGPT or similar systems work. (🙏 Pierre Chapuis)
🪶 Claude Haiku 4.5 released - Benchmarks for Haiku 4.5 showed impressive performance improvements, demonstrating quality output at efficient pricing.
🙌 Debate on Opus vs Sonnet 4.5 continued - Community members discussed the merits of Claude Opus 4.1 versus Sonnet 4.5, with some feeling Opus remained superior regardless of cost. Others noted that Sonnet’s speed advantage and benchmark performance made it preferable for many use cases. (🙏 Robert Hommes @ Moyai, Pierre Chapuis)
MLOps
🧪 The Case for the Return of Tine-Tuning - After years on the sidelines, fine-tuning may be entering a renaissance. New tools, new approaches, and a growing desire for control could spark a shift from generic to bespoke AI. (🙏 Kevin Kuipers, with contributions from Robert Hommes @ Moyai, Benjamin Trom @ Mistral AI, Etienne Balit & Constant Razel @ Exxa, Cédric Deltheil @ Finegrain, and Willy Braun @ Galion.exe)
Robert Hommes’ quote: “Theoretically, fine-tuning has always made sense. But the speed at which closed-source labs were scaling their model intelligence made it a practically bad bet. Now, with compute, data, and better frameworks, the scales are tipping back toward specialization.”

😡 Andrew Ng wants proper evaluation - In his newsletter, Andrew Ng expressed frustration with teams chasing new technology rather than taking time to do proper evaluations and figure out what could actually be improved. He advocated for rigorous testing and measurement.

Programming
📚 Vibe Coding book announced - from industry veterans Steve Yegge and Gene Kim. The book explores how programmers can now describe what they want and watch it materialize instantly. (🙏 Pierre Chapuis)
📈 GLM-4.6 adoption exploded in China - Chinese AI model GLM-4.6 experienced unprecedented growth, jumping from 168 million to 15.9 billion tokens in just 12 days - a 94-fold explosion representing one of the fastest adoption curves seen for any open source model.
GLM-4.6 from Zhipu AI just proved you can build frontier AI without NVIDIA chips, charge 2% of Western prices, and still rank fourth globally. The AI market isn’t what we thought it was
Robotic
🤖 Robot Learning tutorial released - Comprehensive robot learning tutorial launched covering how modern machine learning techniques integrate with classical robotics to create autonomous systems. The tutorial navigated the landscape of modern robot learning with all source code available. (🎉 Francesco Capuano @ Hugging Face)

👩💻 GitHub

🙌 New Members
🇫🇷 Jeremie Kalfon - PhD @ Institut Pasteur & ENS working on computational biology and applied mathematics. He focused on ML and AI applied to target discovery to understand disease mechanisms. Finishing his PhD on foundation models in single-cell RNA-seq. Enjoys various sports including tennis, running, biking, boating, swimming, and skiing. Special powers include cooking and building things.
🇫🇷 Nikolay Tchakarov (Asteria) - CTO at Asteria, a B2B SaaS biomimicry platform. After 12 years in London using ML to predict financial markets, he pivoted to data and AI engineering. Co-founded Asteria as CTO. In his free time, he enjoys climbing, surfing, tennis, and craft beer. Can write and draw with both hands.
Thanks for writing this, it clarifies a lot. I especially appreciate Karpathy's pragmatic view on agents today lacking intelligence and multimodality. What do you see as the single biggest blocker for their wider adoption in the next few years?