
Your Dose of Reg.exe, Week {13}
Reg.exe is a global, closed community of 260+ engineers, founders, and researchers in AI—from San Francisco to Tokyo. Each week we share discussion highlights in a short newsletter.

👉 What is Reg.exe and how to join.
Events
🇬🇧 Engineering Nights #7 with stellar line-up: Christian Ryan (Anthropic), Vincent Moens (Periodic Labs) and Jules Belveze the globetrotter (Dust)
📆 October 7th, in London, Shoreditch
🇬🇧 Inference & vLLM meetup. After successful meetups in Paris, Exxa is expanding to London with talks on inference optimization, speculative decoding, and AI hardware.
📆 October 20th, in London
🇫🇷 Meta, SNCF Connect & Tech, and Hugging Face launched AI Startup Accelerator (in French only) - The third edition of the program at STATION F supports French startups integrating open-source foundation models.
Five startups will be selected between January and June 2026
They will receive technical mentorship, access to Hugging Face’s platform, and opportunities to work on SNCF Connect & Tech’s key challenges.
📆 Applications close October 31, 2025 👉 Register now!
Achievements
🔬 Periodic Labs was announced with the goal of creating the first true AI scientist and autonomous laboratories for accelerated scientific discovery. (🔥 Congrats Vincent Moens @ Periodic Labs).
Focusing on physical sciences to discover breakthrough materials like higher-temperature superconductors and solve real industry problems (already working with semiconductor manufacturers on chip heat dissipation).
Launching an Academic Grant Program to support pioneering research while building autonomous labs.
🎙️ Community-1 diarization model launched - PyannoteAI released a new open-source speaker diarization model as part of pyannote.audio 4.0, representing a significant advancement in open-source speaker intelligence. (🔥 Congrats Hervé Bredin @ PyannoteAI)
The new exclusive mode makes aligning speakers with STT much easier.
The model is available locally or on the pyannoteAI platform for quick switching.
Training is faster and more efficient thanks to new metadata caching and dataloaders.
Computer Vision
🎞️ OpenAI unveiled Sora 2, marking a breakthrough in generative video realism, and a new approach to user experience with a social consumer app (🙏 Pierre Chapuis, Kemal Toprak Uçar)
New standard for photorealistic video generation, 👀 with CCTV-style demos causing viral attention for their authenticity.
Launch debuts as a social iOS app, invite-based, focused on creation.
Remixable video creation, enabling users to modify and extend any clip using text prompts.
Available now in the US and Canada only so far.

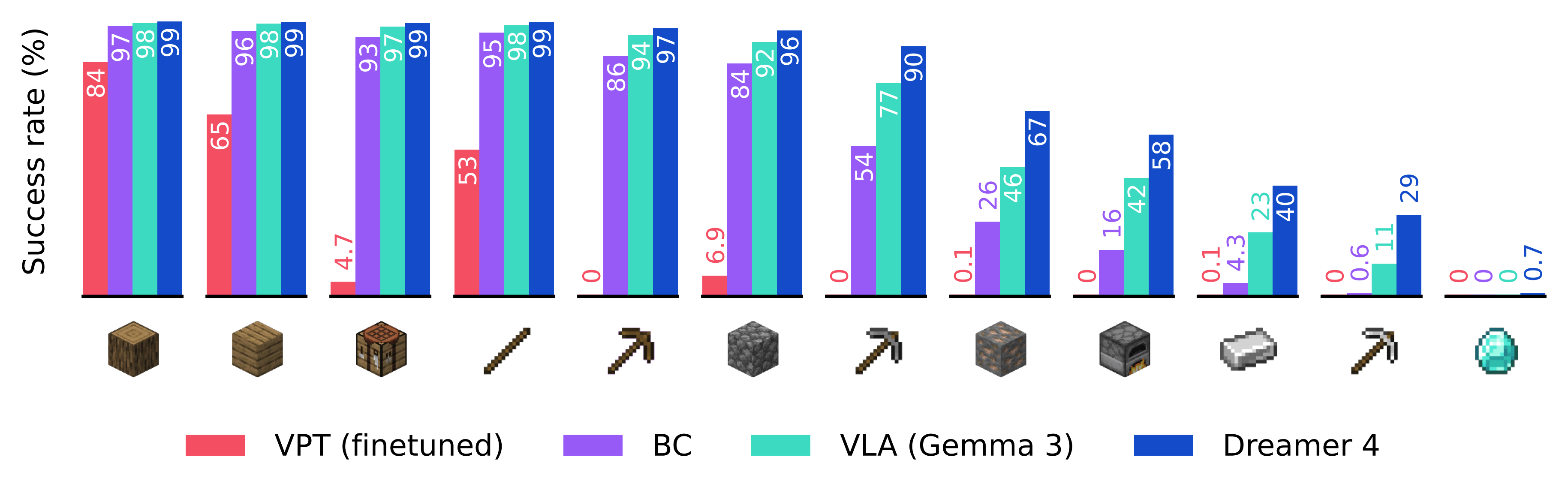
🎞️ Dreamer 4 release – Dreamer 4 is a scalable AI agent that learns to solve control tasks by training inside a fast and accurate world model, using imagination rather than real environment interaction. (🙏 Pierre Chapuis @ Finegrain)
It’s the first agent to obtain diamonds 💎 in Minecraft using only offline data, without interacting live with the environment: a milestone for world model RL agents.
Dreamer 4 significantly outperforms OpenAI’s VPT offline agent, while using 100 times less data. It also outperforms modern behavioral cloning approaches based on finetuning general vision-language models.
🔬 53x Faster Flux generation – Research achieved dramatic compression speedups for generative video models. (🙏 Gabriel Olympie @ Reg.exe)
Model compression enabled a 53× increase in inference speed without sacrificing fidelity.
Allows real-time generative video pipelines, paving the way for on-demand content.
Compatible with advanced video world models such as Wan 2.2 and Sora architectures.
Lower carbon impact and computational cost support sustainable deployment.
Sets a precedent for rapid and efficient deployment of generative AI systems.
“That’s huge, 53x faster flux generation apparently through model compression, and compatible with video model. This might mean real time video generation with Wan 2.2!”, Gabriel Olympie (Reg.exe)
🤓 Apple pivots to AI glasses – Apple shifted focus from Vision Pro VR to developing wearable AR glasses. (🙏 Kevin Kuipers, Pierre Chapuis, Ali Khosh @ Meta-Reality Labs)
Investment redirected to lightweight, AI-driven augmented reality products.
At least two types of smart glasses are in development, targeting broader consumer adoption.
Emphasis placed on context-aware, voice-assisted ambient computing.
Internal teams prioritize design and user experience for AI wearables.
Marks Apple’s strategic commitment to AR over immersive VR hardware.
Language Models
🧠 Reinforcement Learning on Pre-Training Data (RLPT) introduced - a new paradigm tackling the data scarcity problem as compute scales faster than available text. The method leverages Autoregressive Segment Reasoning (ASR) and Middle Segment Reasoning (MSR) to improve models without human annotations, showing gains across reasoning and in-context prediction tasks. (🙏 Kevin Kuipers @ Reg.exe)
ASR: compares generated segments to the original source using a generative reward model to assess semantic consistency.
MSR: masks the middle of a sentence, generates the missing part, and evaluates the reconstruction.
Overall, the approach delivers measurable improvements, without any human supervision, unlike SFT, RLHF, or RLVR, which rely on varying degrees of manual labeling.
🧑🔬 Thinking Machines Lab launched Tinker API - A flexible API for fine-tuning AI models with managed infrastructure. The Model-as-a-Service approach enables customization for specialized tasks with built-in fine-tuning. (🙏 Robert Hommes @ Moyai, Kevin Kuipers)
You can switch between small and large open-weight models easily, including mixture-of-experts models like Qwen-235B-A22B.
Managed service: Tinker handles compute, scheduling, and infrastructure; uses LoRA to share resources and reduce costs.
Major research groups have already used Tinker for theorem proving, chemistry reasoning, async RL, and AI control tasks; private beta starts now, free to try, waitlist open.
👀 Is diffusion the future of LLMs? - A (tiny) deep dive in computer vision models to explain why progress shows regularly visible leaps, while LLMs feel static and slow by comparison. (Kevin Kuipers @ Reg.exe)
LLMs scale via brute-force but face a looming shortage of high-quality text data while vision models achieve more with fewer parameters and greater architectural variety.
Diffusion models offer key advantages (bidirectional context, error correction, and parallelism) but adapting them to text remains technically hard.
")
")
Also:
🛍️ OpenAI enabled instant checkout in ChatGPT - New agentic commerce capabilities introduced, allowing users to shop directly within ChatGPT with instant checkout functionality. (🙏 Sacha Morard @ Edgee)
🛠️ oLLM library launched - Lightweight Python library for LLM inference built on transformers, enabling models like Qwen3-Next-80B, GPT-OSS, and Llama3 to run on consumer hardware.
☑️ K2 Vendor Verifier released - Kimi Infra team’s tool enabled visual comparison of tool call accuracy across providers on OpenRouter, helping developers benchmark model performance. (🙏 Mishig Davaadorj @ Hugging Face)
📉 OpenAI launched GDPval framework - It evaluates AI performance on real-world, economically valuable tasks, OpenAI’s GDPval shows that recent AI models perform real-world, high-value tasks at near-expert quality, much faster and cheaper than humans.
Autonomous Agents
📰 The cost of tool calling - LLM tool calls are fundamentally expensive because each tool call requires text generation, consuming both computational resources and valuable context window space. While tool calling enables powerful agentic systems, the traditional programming approach of making many function calls in loops becomes impractical for agents due to these cost and context limitations. (🙏 Nnenna Ndukwe @ Qodo, Kevin Kuipers @ Reg.exe)
If you’re adding 2 numbers once, it probably doesn’t matter. If you’re summing up 1,000 numbers… you’re going to be waiting a very long time for those 999 tool calls to finish, and you might blow through your entire context window. (...) Maybe you can sidestep this problem by letting your agent write+run code (keeping in mind all of the necessary security precautions).
Tool calls in LLMs are much more computationally expensive than regular function calls.
Each tool call consumes significant context window space, quickly limiting memory for agents.
Common programming loops (like processing many items) can hit practical limits due to tool call constraints.
Prefer designing batch-capable or flexible tools to handle complex operations in fewer calls.
🙏 Nnenna recommends CrewAI for getting started and local projects but points out that LangChain is what’s currently used in production at Qodo.
🎛️ Infrastructure
🍿 Netflix’s AV1 streaming efficiency analyzed - Deep dive into how Netflix quietly revolutionized streaming with AV1 codec, revealing 10 key discoveries about their compression algorithms and efficiency improvements.
🧠 AMD’s Iris framework introduced for multi-GPU programming - New approach with three key innovations: GPU-initiated communications (removing CPU bottleneck), symmetric heap architecture (enabling direct inter-GPU data access), and device-side synchronization. The framework brought more structural symmetry compared to Nvidia’s NVSHMEM, which isn’t supported by default in older frameworks. (🙏 Matt Suiche)
🤖 Robotic
🤖 OpenGalaxea huge dataset - Large-scale robotics dataset featuring real-world scenarios, dual-arm manipulation, and whole-body control data under CC BY-NC-SA 4.0 license. (🙏 Harsi Singh Sandhawalia @ Yaak)
500+ hours of real-world mobile manipulation data.
All data collected using one uniform robotic embodiment for consistency.
Fine-grained subtask language annotations.
Covers residential, kitchen, retail, and office settings.
Dataset in RLDS format.
👀 RDT-2 achieved zero-shot cross-embodiment generalization - First foundation model capable of zero-shot deployment on unseen robot embodiments for simple open-vocabulary tasks like picking and placing objects. Enabled by scaling up UMI data collection methods. (🙏 Harsi Singh Sandhawalia @ Yaak)


🤩 Must see: the Limx Dynamics Oli humanoid (“for a price of a small car”, Pierre Chapuis) and China’s G1 humanoid demo
Programming
🧠 “The Kumbaya Paradox” analyzed vibe coding movement - Analysis argued that the movement’s promise to make everyone productive through part-time coding won’t move the needle for 99% of non-tech professionals. The real problem isn’t who codes, but what gets coded. (🙏 Julien Mangeard @ Plakar)
👩💻 Claude Sonnet 4.5 released as best coding model - Anthropic launched Claude Sonnet 4.5, positioning it as the world’s best coding model, strongest for building complex agents, and best at computer use. The model showed substantial gains in reasoning and math capabilities. (🙏 Robert Hommes @ Moyai, Charly Poly @ Inngest)
“Claude Code just killed Cursor’s major feature with their breakpoints support” Charly Poly @ Inngest
Also:
📚 AI development patterns repository published - Comprehensive collection of AI-assisted software development patterns organized by implementation maturity and lifecycle phases, including Foundation, Development, and Operations patterns with practical examples and anti-patterns. (🙏 Nnenna Ndukwe @ Qodo)
Cursor 1.7 introduced agent autocomplete and browser controls - Major update enabled Cursor to control browsers for taking screenshots, improving UI, and debugging client issues. Autocomplete suggestions appeared when writing prompts based on recent changes.
opencode + GLM 4.6 emerged as Claude Code alternative - Combination provided Claude Code-like functionality at insanely cheap prices with better terminal UI. Now supports Hugging Face tokens for authentication.
Geographic Hubs
🇫🇷 Lyon TechLunch.exe discussed at LDLC’s HQ!
🇺🇸 San Francisco members active - Arnaud Breton, Daniel Huynh, and Louis Abraham
🇸🇪 Stockholm: Great to see François Lecroart @ Lemlist and Timothy Lindlom @ Natively enjoying a drink by the NordicJS.


New Members
🇫🇷 Joffrey Villard - Software Engineering @ Collibra. Information theory PhD turned Data Analyst and Software Engineer, former co-founder at Husprey. Based in Lyon, France.
🇳🇱 Thomas Kluiters - AI @ Juvoly, working on SOTA European STT for healthcare. Software engineer turned AI engineer specializing in speech model inferencing and training. Based in Leiden, Netherlands.
🇳🇱 Alina Dumitrache - from Clobr and talented operator of the Tech Makers’ tech community. If you’re in Amsterdam, reach out to her.