
TTY-changelog #050
Claude Sonnet 5 shipped and Fable 5 returned, Google launched Nano Banana 2 Lite and Omni Flash, Gemma 4 ran in-browser, and Meituan's LongCat-2.0 claimed the first domestic-chip training.

👉 Article originally posted on TTY
Events
🇺🇸 Holo AI Night in San Francisco (July 13) – The first Holo AI Night, a technical meetup with short talks from NVIDIA, Black Forest Labs, and H Company after a weekend hackathon.
Autonomous Agents
🎨 OpenPencil design tool with agent teams – An open-source, AI-native vector design tool where an orchestrator splits a page into spatial sub-tasks that parallel agents build at the same time on a live canvas. It ships Design-as-Code JSON files, a built-in MCP server, and export to React, Vue, Flutter, and more.
Biotech, Health, and Chemistry
🔬 Claude Science research workbench beta – A public beta app, not a new model, that runs analyses, queries 60 plus scientific databases, and welds every figure to the exact code and environment that produced it for reproducibility. It comes pre-configured for genomics, single-cell, proteomics, and cheminformatics, running where the data lives on macOS and Linux.
Image, Video & 3D
🍌 Nano Banana 2 Lite, Omni Flash – Google DeepMind shipped two models: Nano Banana 2 Lite, its fastest and cheapest image model at roughly four-second text-to-image, and Gemini Omni Flash for high-quality video generation and editing through the Gemini API and AI Studio. An Interactions API chains an image into an animation with up to three stacked edits.

🌀 Un-0 generates images with oscillators – An image generator that lets physics do the computing, using a network of synchronizing oscillators instead of GPU math in a bid for roughly 1,000x better energy efficiency. It matched the quality of early leading conventional image methods, and the weights and code are open.
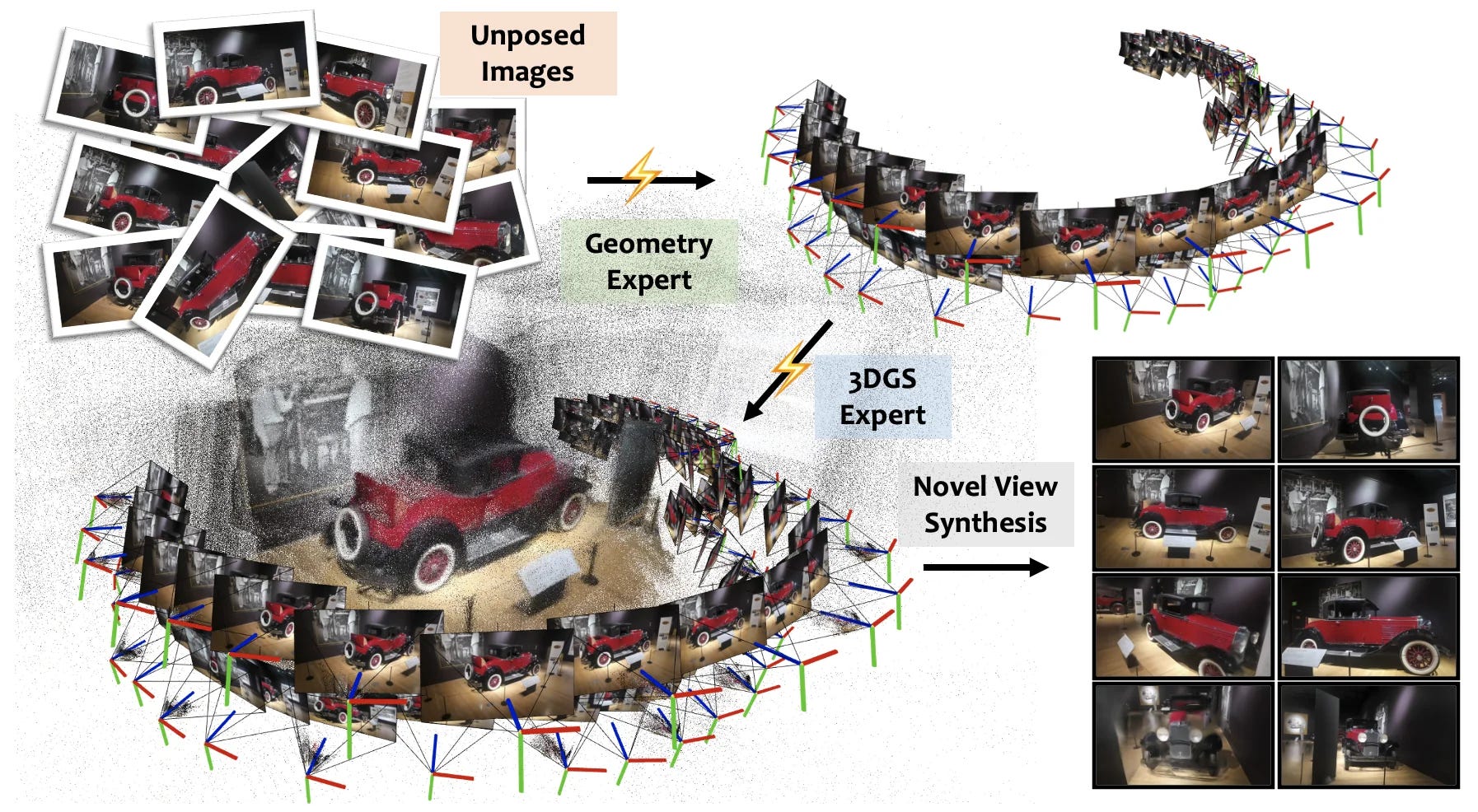
🧊 2Xplat splits geometry from appearance – A pose-free feed-forward 3D Gaussian Splatting method built from two experts: a geometry expert predicts camera poses from uncalibrated multi-view images, then an appearance expert synthesizes the Gaussians. In under 5K training iterations it beat prior pose-free methods and matched state-of-the-art posed approaches.
Infrastructure
📊 State of the AI economy report – A bottom-up, deduplicated reconstruction of AI demand built from company filings, not hype. Generative AI revenue has passed a $175bn annualized run rate, growing about 3.2x a year, yet still equals only 0.42% of US GDP. The open question is whether falling prices move enough volume to repay the buildout.
🖥 Running frontier LLMs locally – A hardware and serving guide for local inference: roughly $2k of dual RTX 3090s runs a 27B model plus speech-to-text, while about $40k of RTX PRO 6000s runs GLM-5.2-594B near Opus intelligence at around 80 tokens per second. It covers PCIe peer-to-peer, BIOS tuning, and ready-to-run Docker configs.
Language Models
🛡 Fable 5 redeployed after export controls – Anthropic restored Claude Fable 5 on July 1 after US export controls were lifted, adding an improved safety classifier that reroutes flagged requests to Opus 4.8 with user notification. The models had been suspended June 12 after a reported safeguard bypass. Fable is free for part of weekly usage through July 7.
Community take w/ Pierre Chapuis: “Even Opus is barely usable right now. I keep getting ‘safeguards flagged this message for a cybersecurity topic’ just because I debug crashes.”
🚀 Claude Sonnet 5 ships as default – Anthropic introduced Claude Sonnet 5, its most agentic Sonnet, able to plan and use browsers and terminals autonomously at a level that recently needed larger models. Performance sits close to Opus 4.8 at lower prices, and it is now the default on Free and Pro with introductory pricing through August 31.
🌐 Gemma 4 runs in-browser via WebGPU – A Hugging Face Space runs Gemma 4 E2B fully on-device in the browser through WebGPU, with the kernels written and optimized entirely by Fable 5. Weights cache locally after first load and nothing typed leaves the machine. It reports 2.3B effective parameters, 128K context, and roughly 250 tokens per second on an M4 Max.
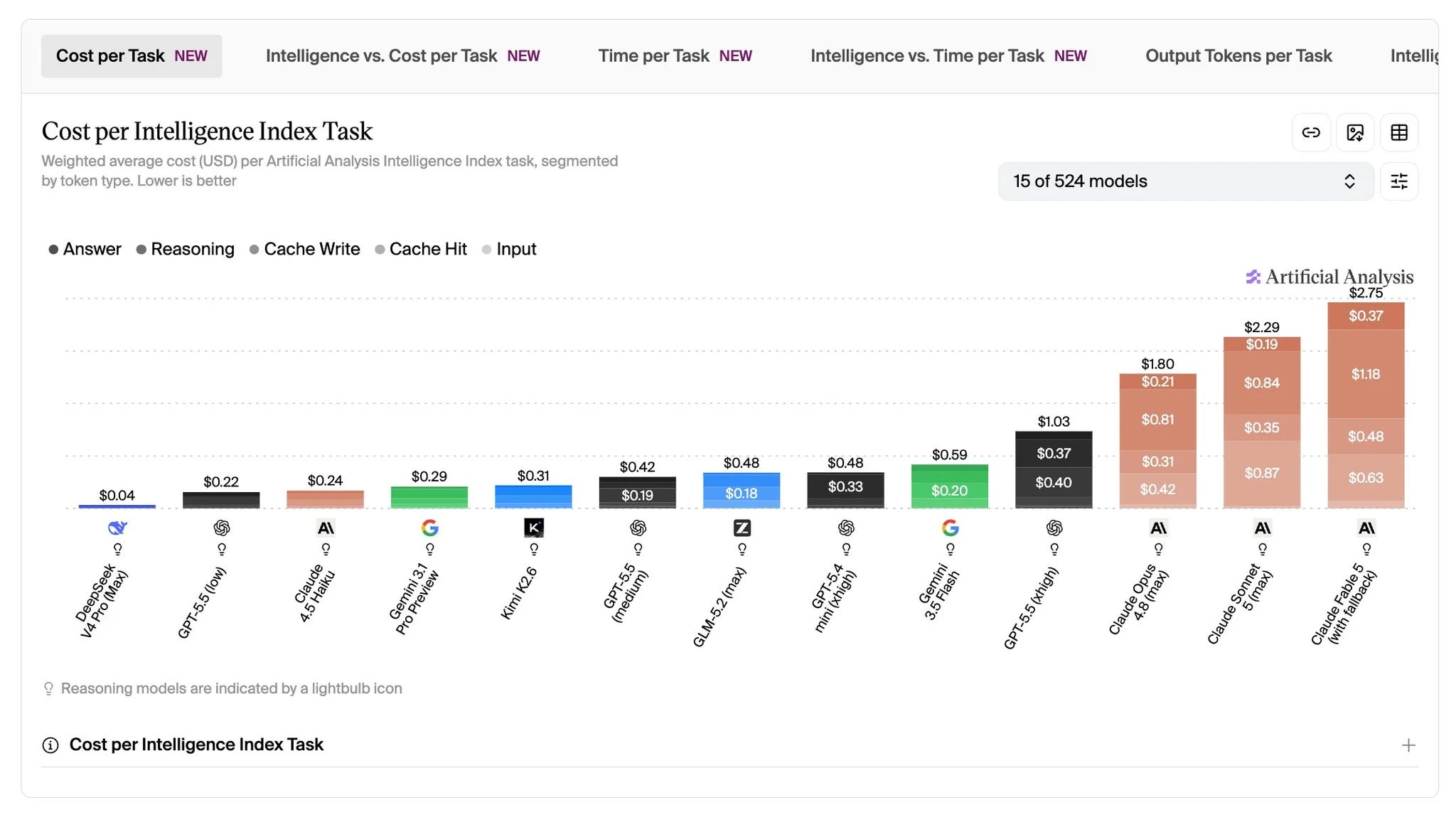
💸 Does Sonnet 5 cost more than Opus? – A widely shared thread argued that on the Artificial Analysis Intelligence Index, Sonnet 5 cost more per task than Opus 4.8, generating almost twice as many tokens, so a cheaper-per-token model ran up a higher benchmark bill, in one run even pricier than Fable.
🇨🇳 Meituan trains LongCat-2.0 on domestic chips – Meituan launched LongCat-2.0, a 1.6-trillion-parameter model with a one-million-token context window, and said it was the first of its size pre-trained and served end-to-end on a 50,000-chip domestic cluster. It claims performance comparable to Gemini 3.1 Pro, and the weights were open-sourced.
📚 Not all context is knowledge – Notes on fine-tuning a small local knowledge-management model that beat a frontier API at its trained task: a fine-tuned 8B model scored 81% versus 76% zero-shot for a frontier model, at roughly 5x lower latency and cost. The thesis is that putting a file in context is not the same as the model knowing it is correct and current.
MLOps
🗜 Edgee Compressor V2 cuts token cost – A token-compression layer in an AI gateway, measured end-to-end on SWE-bench Lite, that stacks three independent strategies: output brevity, tool-surface reduction, and tool-result trimming. Each targets a different source of token bloat, validated with paired statistical tests, for up to around 50% cost reduction.
⚙️ What happens running a CUDA kernel – A roughly 35-minute walkthrough tracing one CUDA vector-add kernel from source through the nvcc compiler pipeline down to the warps that execute it: PTX and SASS lowering, constant bank 0, the QMD structure, nine hundred ioctls, and a memory-mapped doorbell register.
Programming
🧭 Advisor pairs Sonnet 5 and Fable 5 – A pattern where Sonnet 5 runs the agent loop cheaply at near-Opus capability and calls Fable 5 only on hard decisions for frontier judgment on demand. In testing, agents made better architectural calls and runs got cheaper because better plans meant fewer turns. It is available in Claude Code via the advisor command.

🧫 Tau teaches how coding agents work – An educational Python coding agent you read like a textbook, built in three layers: provider-neutral streaming, a reusable agent loop, and a coding environment with files, shell, sessions, and a terminal UI. Its core idea separates the reusable brain from the environment and the frontend.
⌥ oh-my-pi wires IDE into terminal agent – A terminal coding agent with a full IDE wired in: it makes precise edits, safely renames across a codebase, drives a real debugger to step through crashes, runs persistent Python sessions, spins up subagents, and keeps a second model reviewing every turn. 15.8k stars, MIT.
🔀 Devin Fusion cuts cost with sidekicks – A multi-model coding harness using a sidekick pattern: a frontier main agent delegates subtasks to a cheaper parallel agent, each keeping its own cached context, with dynamic mid-session routing at compaction. It reported frontier-level quality at roughly 35% lower cost on a new correctness-and-quality benchmark.
Reinforcement Learning
🐦 Ornith-1.0 learns its own scaffolds – An open-source family of coding models that learns to write its own agent scaffolding, the orchestration usually built by hand, while it learns to solve tasks. It ranges from small edge models up to a frontier-scale version that matched Opus 4.7 on coding benchmarks.
Robotic, World AI
🤖 UBTech U1 companion humanoid launches – UBTech, the first publicly traded humanoid maker, unveiled the U1, a consumer companion robot with lifelike silicone skin and emotional AI, in male and female versions, part of a broader Chinese push to move robots from the factory into the home.

Contributors This Week
Pierre Chapuis, Amine Saboni, Gabriel Olympie, Robert Hommes, Nancy Wang, Stéphane Collot, Gabriel Duciel, Quentin Dubois, Daniel Madalitso Phiri, Etienne Balit, Ihab Bendidi, Jocelyn Fournier, Jules Belveze, Sacha Morard, Victoria Latynina