
TTY-changelog #048
GLM-5.2 took the open-weight lead, Sakana Marlin shipped an autonomous research agent, the US suspended Fable and Mythos, and Midjourney pitched a whole-body health scanner.

👉 Article originally posted on TTY
Autonomous Agents
🤖 Sakana Marlin runs autonomous research – Given only a theme, the new product researched for up to eight hours and returned summary slides and a multi-dozen-page report. Pitched as a virtual chief strategy officer, it built on prior AI Scientist, AB-MCTS, and ALE-Agent work and 300 beta testers.
Community take: The community welcomed it, saying deep-research tools from current providers turn superficial once you push for technical depth and that he often loops through 8 to 10 reports to get there, so getting that in one prompt appeals.
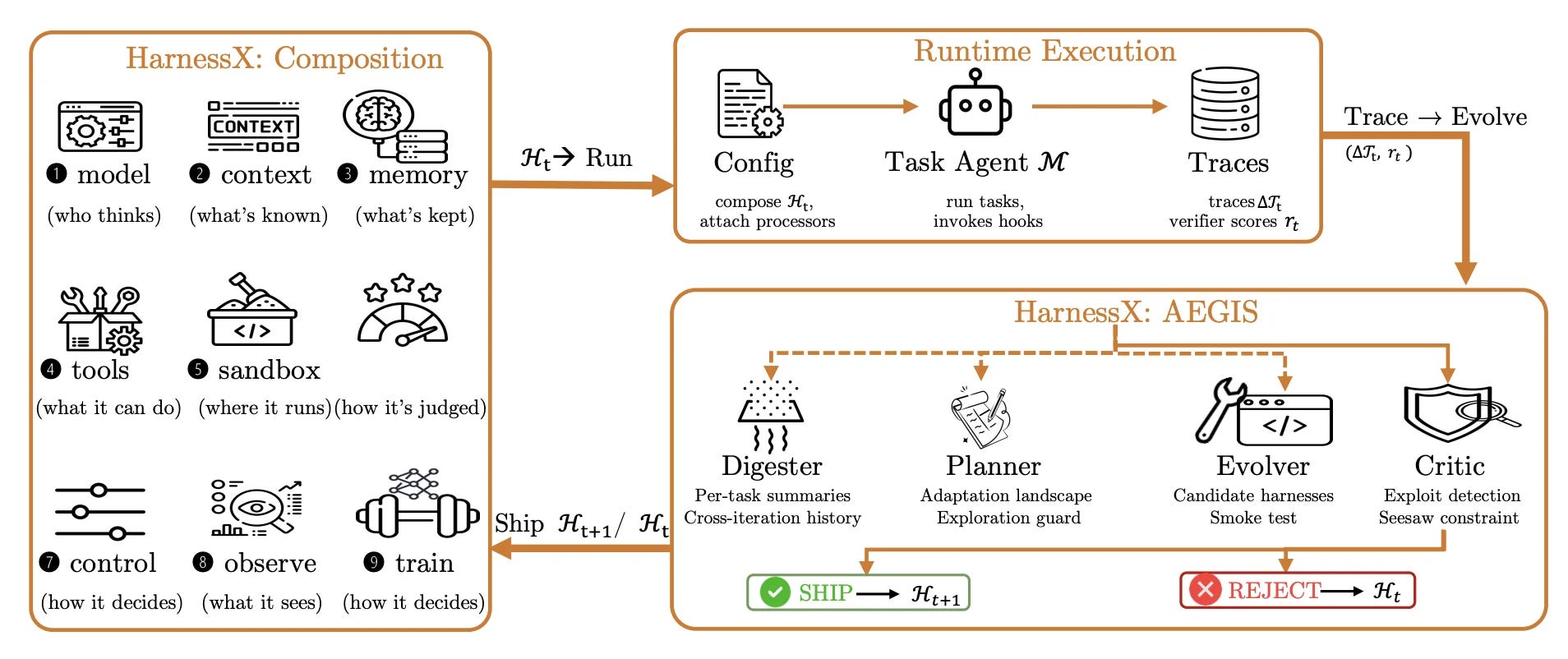
🛠️ HarnessX builds evolvable agent harnesses – A June paper introduced a foundry that assembled agent scaffolding from typed primitives and refined it from execution traces. Across five benchmarks it raised results 14.5% on average and up to 44%, arguing scaffolding rivals model scaling.
Biotech, Health, and Chemistry
🏥 Midjourney Medical unveils whole-body scanner – The new medical line used ultrasonic waves in a pool of light to build MRI-like 3D body maps in about 60 seconds, roughly 100x faster than today’s MRI. Scans would happen inside relaxing spa locations open around the clock.
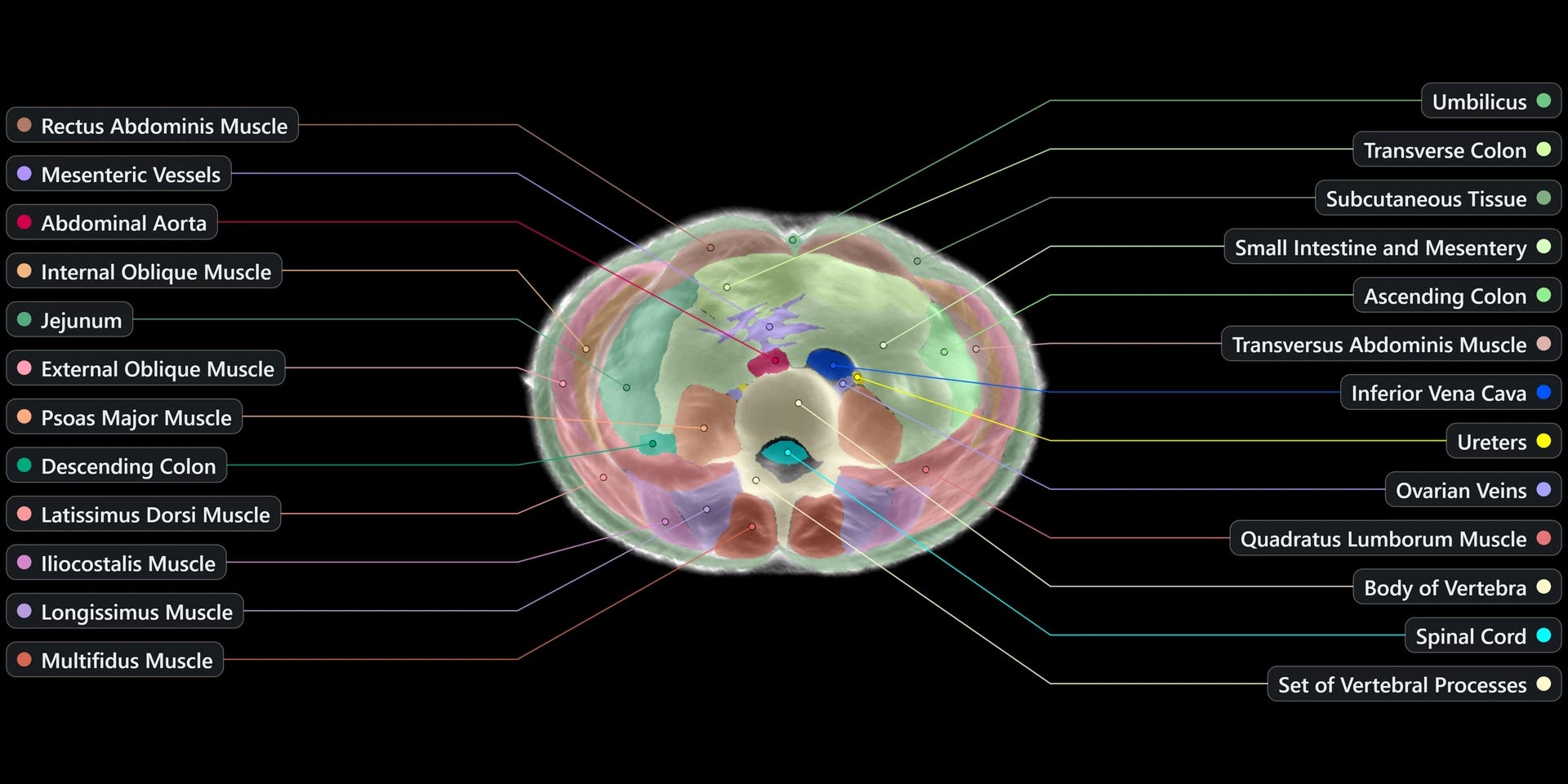
The first spa is planned for San Francisco in 2027, with body-composition mapping submitted for FDA approval first.
The lab framed itself as community-backed with no investors, funded by everyday people.
Its 2031 goal was a fleet of 50,000 scanners delivering a billion scans a month.
Community take: Pierre Manceron described it as a fun and impressive move, but noted that a radiologist on their team was puzzled by obvious anatomical mistakes, including reversed organs. They also pointed out that synthetic CT and MRI generation is neither a new problem nor a solved one, while still believing the company could make meaningful progress. Others were more skeptical, suggesting that AI companies sometimes pursue biology-related projects to reinforce growth narratives. Although, for Pierre Chapuis, Midjourney may be a special case. The company has been a leader in image generation for years, remains independently funded, and has generated hundreds of millions in revenue, making its motivations and position somewhat different.
Image, Video & 3D
🎬 Bernini unifies video generation and editing – ByteDance released the framework, pairing a multimodal language planner with a diffusion renderer for prompt edits, reference-guided edits, content insertion, and reference-to-video from up to five images. A segment-aware encoding kept visual parts distinct.
Cyber
🚫 US suspends Fable and Mythos access – Last weekend, a US government export-control directive forced Anthropic to disable Fable 5 and Mythos 5 for everyone over foreign-national access concerns. The trigger was a reported jailbreak of Fable’s guardrails said to unlock Mythos-level offensive security, though Anthropic argued it surfaced only minor, already-known flaws. Much of the community has been skeptical of the official framing. For now both models remain off while Anthropic works to restore access.
🔧 Cursor lifts Fable 5 fix rates – Endor Labs re-ran the model on 200 real vulnerability-fixing tasks using Cursor instead of Claude Code. It topped the fair leaderboard at 72.6% functional and 29% security pass rates, pointing to the harness, not the model, as the driver.
Infrastructure
🔀 OpenRouter Fusion ships multi-model API – The new product queried a panel of models in parallel and used a judge to synthesize one answer. On 100 hard research tasks it beat every solo model, with a budget panel landing allegedly “within 1% of Fable 5 at about half the cost”. OpenRouter team admitted that only one deep-research set was tested, without the long-horizon tasks where Fable stayed strong.
🖥️ Ryzen AI Halo runs models locally – AMD aimed agentic AI at local PCs with two products. The Halo developer platform paired 128GB unified memory to run 200B-parameter models, while the Max PRO 400 chips claimed the first x86 client silicon able to run 300B models locally.
Community take w/ Gabriel Olympie: “The specs do not fit my use cases. It is mostly an Nvidia Spark copycat, with compute roughly equivalent to a four-year-old RTX 3090 and bandwidth limited to 256GB per second, too slow for coding, heavy agentic workloads, or concurrent serving.”
💾 Plakar v1.1.3 ships major update – The release swapped the old agent for a tiny cached service and added a new terminal UI, multi-directory backups, rewritten FUSE and HTTP mounts, and a package manager. Restores ran roughly 95% faster with lower peak RAM and a smaller cache footprint.
Language Models
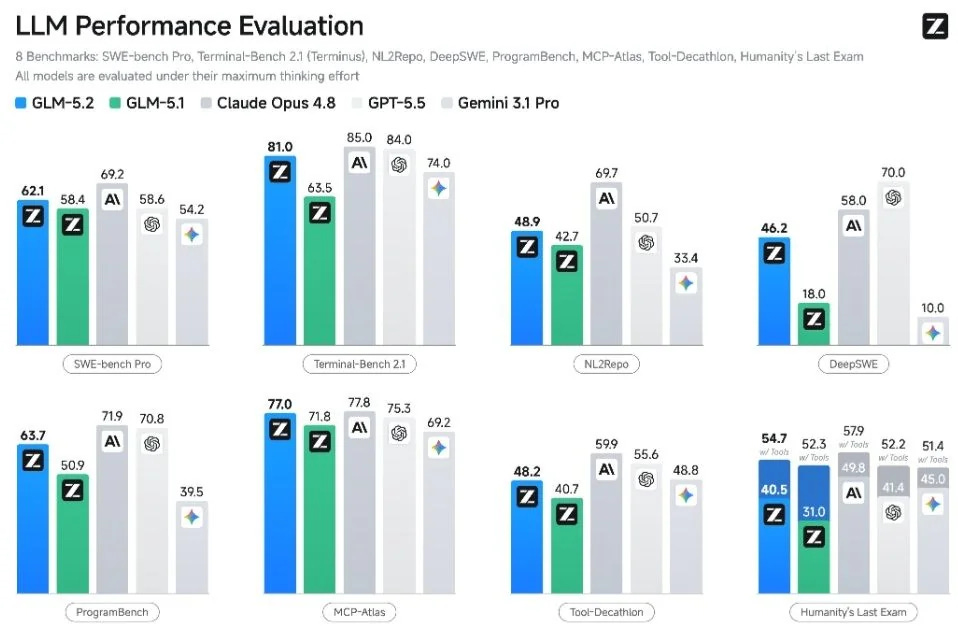
🧠 GLM-5.2 leads open-weight models – Z.ai released the 744B mixture-of-experts model with 40B active and a 1M-token context under MIT license. It topped Artificial Analysis’s open-model ranking at 51 and performed on par with Opus 4.8, GPT-5.5, and Gemini 3.1 Pro. More: Artificial Analysis benchmark.
It led open models on the agentic GDPval-AA v2 benchmark, effectively level with GPT-5.5.
Gains were largest in scientific reasoning, with double-digit jumps on CritPt and HLE.
The context window jumped from 200K to a full 1M tokens.
🪶 Mistral teases sparse open-weight family – The lab teased a new model family for summer 2026, described as large but sparse, with a July early-access program for research, government, and industry partners. The CEO stressed the weights would stay open so customers could inspect and audit systems. The post landed as confirmation of a running community joke about a rumored Mistral model dubbed “Le Chaton Fat.”

💻 Poolside opens Laguna coding models – Previously serving only government and enterprise, the lab released its first public models for agentic coding. The Apache-licensed XS.2 ran on a single GPU and solved 68.2% of SWE-bench Verified, beating Gemma 4, while the larger M.1 reached 72.5%.
📜 SubQ pushes context to 12M tokens – Subquadratic unveiled SubQ 1.1 Small, a sparse-attention model for reasoning over whole codebases and document sets. On their benchmarks, they claim near-perfect retrieval out to that length and at 1M tokens used 64.5x less compute than dense attention, running 56x faster than FlashAttention-2.
Community take w/ Julien Seveno-Piltant: “They do not explain how the SSA mechanism works under the hood. However, they mention building something similar to DeepSeek’s HSA. They also did not train a model from scratch, instead choosing to fine-tune an existing model on an additional trillion tokens.”
MLOps
📦 GLM-5.2 runs locally with Unsloth – Unsloth’s dynamic GGUFs let the 744B model run on local hardware, with 1-bit quantization reaching about 76% top-1 accuracy at 86% smaller and 2-bit about 82% accuracy at 84% smaller. More: Ollama build.
Community take w/ Quentin Dubois: “Running it on Ollama Cloud, it is pretty good and fast with Claude Code.”
Programming
⚡ Why Zig banned AI and left GitHub – In a long interview, Zig’s creator explained why the language still had no 1.0 after a decade, why it left GitHub for Codeberg, and why it banned AI contributions. Zig now powered Ghostty, TigerBeetle, and Uber’s cross-compilation.
📉 More AI code, barely more releases – An analysis of an NBER study on 100,000-plus GitHub developers found autonomous agents tied to 17.3x more lines of code but only 1.3x more releases. The gain shrank at every stage, suggesting the bottleneck moved to review and judgment, not code generation.
Robotic, World AI
🦾 Genesis unveils Eno general-purpose robot – The new robot was pitched as intelligence given a body rather than a machine imitating humans. Its wheeled design sparked debate over form versus function, with the company saying wheels suited most of the early use cases it was exploring.

🌍 γ-World models multi-agent interactive worlds – NVIDIA’s Spatial Intelligence Lab and academic partners built a generative model for several independently controllable agents. A simplex agent encoding and sparse hub attention reached real-time 24 FPS and generalized from two to four players without retraining.
Other topics
🖨️ Morpho previews desktop UV printer – Morpho showed an upcoming desktop UV printer, still marked coming soon rather than shipping. It claimed 2400 DPI on more than 2,000 surface types from flat panels to curved objects, a built-in spectrometer that recalibrates color over time, and runs up to 4.4x faster than rivals.
TTY + Cusp Party

With Cusp Capital, we held a gathering at a cocktail bar in the Sentier (Paris), where 60 members and friends joined us for a hot summer evening.
Thank you all for the great discussions and the banter, for keeping the community alive, and to those of you who made the trip from across France and even Europe to be here with us tonight. I truly appreciate it. 🙏
TTY Lunch

Each week, TTY Lunch brings together exceptional builders around the table. Today’s lineup included Charles Sonigo (Alpic), Guillaume de Luca (ZebraMed), Louis Choquel (Pipelex), Marco Fucci di Napoli (Rowads Studio), Nancy Wang (FluenTea), Sophie Monnier (InstaDeep), Sasha Collin (Lemrock), and Wissam Antoun (Inria).
The discussion focused primarily on integrating AI through agents, workflows, and productivity tools, managing AI costs and infrastructure decisions, and improving the AI development and review cycle.
Contributors This Week
Gabriel Olympie, Pierre Manceron, Nancy Wang, Pierre Chapuis, Quentin Dubois, Félix Raimundo, Julien Seveno-Piltant, Robert Hommes, Ihab Bendidi, Karim Matrah, Amine Saboni, Arnaud Thiercelin, Benoit Kohler, Carlos Fernandez Musoles, Fabien Niel, Jeremie Kalfon, Stéphane Collot, Vladimir de Turckheim, Wissam Antoun, Sasha Collin, Marco Fucci di Napoli, Charles Sonigo, Guillaume de Luca, Louis Choquel, Sophie Monnier