
TTY-changelog #039
MCP design debate accelerates, flow matching unifies with diffusion, biotech specialists challenge generalist models, coding agents reshape development workflows, and robotics makes gains.

👉 Article originally posted on TTY
Events
🇧🇷 TechBio Social at ICLR in Rio (Apr) – Valence Labs and the LMRL Workshop host a TechBio gathering for ICLR 2026 attendees in Rio de Janeiro.
Audio
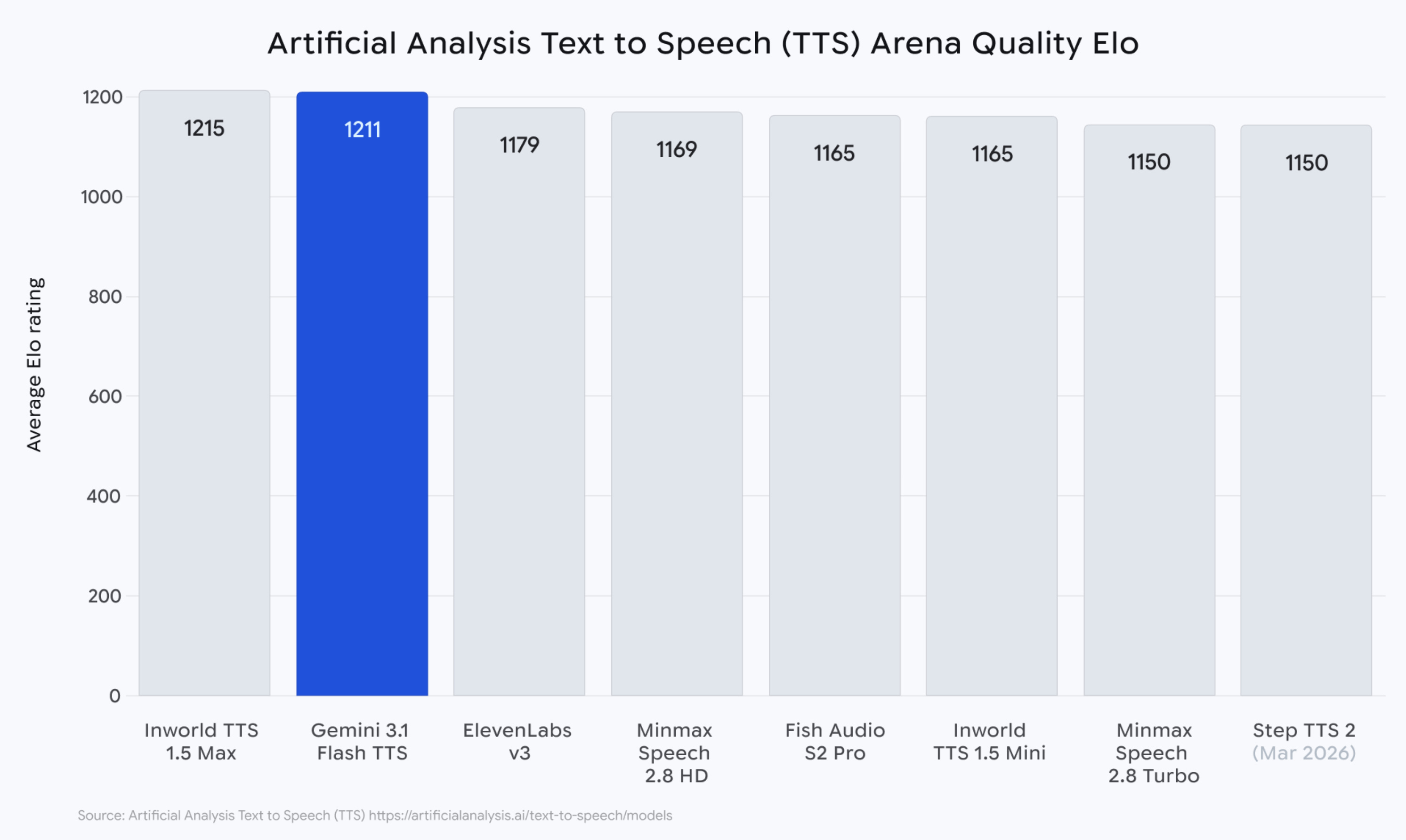
🎙 Gemini 3.1 Flash TTS launched – Google shipped Gemini 3.1 Flash TTS in Gemini API, AI Studio, Vertex AI, and Google Vids, scoring an Elo of 1,211 on Artificial Analysis’s blind-preference TTS leaderboard. New audio tags let developers steer vocal style, pace, and delivery with natural-language commands embedded in the text input, alongside native multi-speaker dialogue, support for 70+ languages, and SynthID watermarking on all outputs.
🎓 CS153 guest lecture by ElevenLabs – Stanford’s Frontier Systems class hosted ElevenLabs co-founder Mati Staniszewski walking through the company’s early days, part of a recommended lecture series covering today’s frontier infra teams.
Autonomous Agents
🎛️ The MCP design debate – A week-long thread reframed how to think about MCP servers. A Cloudflare post by Kenton Varda and Sunil Pai argues that the prevailing pattern of exposing MCP tools directly to LLMs is flawed. LLMs have seen vast amounts of real world TypeScript, but only a narrow, artificial set of tool calls. Their approach converts MCP tools into a TypeScript API, has the LLM write code against it, and runs that code in a V8 isolate sandbox where MCP servers are exposed as bindings rather than accessed over the network.
Phil Schmid’s counterpoint argues that MCP is not the problem, but poorly designed servers are. He frames MCP as an agent-facing UI rather than a REST wrapper, and outlines principles such as designing tools around outcomes, simplifying inputs, treating descriptions and errors as core context, limiting the number of tools, using explicit naming, and avoiding large unstructured outputs.
The naive OpenAPI2MCP pattern of one endpoint per tool is the shared punching bag: both the code-mode and best-practices camps agree it fails under real workloads because MCP is a user interface for agents, not a basic REST wrapper.
A pragmatic middle ground surfaced: design MCP servers around the workflows users and agents actually need, keep a search-and-execute path for the unanticipated, and evaluate servers by pass^k on frequent tasks.
Community take w/ Sebastien Charrier (Bump.sh): “I’m not convinced by the 100% code mode for all use cases. If the LLM has to build the code wrapper at runtime, it can result in very poor performance. It can work in a dev process because you accept waiting a few minutes, but for end-users consuming your service through MCP it’s not acceptable.”
🤖 Rethinking agent evaluation as a production system – Jules Belveze argues the current paradigm is breaking down: static datasets decay, benchmarks get gamed, and they fail to capture real outcomes. He suggests evaluation should emerge from the platform itself, leveraging production traces, feedback, and version history rather than separate benchmarks. He outlines three directions: behavioral fingerprinting based on execution consistency, a feedback flywheel that turns failures into minimal reproduction tests, and outcome signals such as user return, escalation to humans, and increasing task complexity over time, with static benchmarks remaining useful but secondary.

🎲 Property-based testing for agentic coding – Anthropic’s Frontier Red Team presented an agent that infers code properties from docstrings, type hints, and comments, then generates property based tests using Hypothesis. The goal is to automatically discover bugs by stress testing these inferred properties with large numbers of edge case inputs, rather than relying on hand written tests.
📱 Gemma 4 edge agent skills – Google claims Gemma 4 brings advanced agentic AI to devices, enabling multi-step planning, autonomous actions, and multimodal tasks on-device. Open under Apache 2.0, it supports 140+ languages and runs efficiently across mobile, desktop, and IoT hardware.
Biotech, Health, and Chemistry
🧬 OpenAI ships GPT-Rosalind biology LLM – OpenAI released GPT-Rosalind, a version of its model trained on how biologists actually work and on the big public biology databases. It is built to push back when a researcher proposes a bad idea instead of agreeing just to be helpful. Only approved US teams get access for now, with a lighter research plugin open to everyone else.
Community take w/ Maziyar Panahi: “I’ve tried Claude for Health. The skills are mediocre at best, and without third party MCP servers they are basically useless. It is disappointing, especially since they have not been updated in 3 to 4 months. Meanwhile, OpenAI’s latest podcast hints at deeper industry partnerships and specialized models and tools for life sciences that Codex can orchestrate. That direction might explain why Anthropic is acquiring biotech startups.”

Image, Video & 3D
🌊 ByteDance’s paper and flow model discussion – The Continuous Adversarial Flow Models paper by Shanchuan Lin takes an existing flow matching model and trains a second “critic” network alongside it to judge whether generated images look real. After just 10 extra training passes, image quality on ImageNet improved dramatically. The paper triggered a week-long community thread on why flow matching and diffusion, the two dominant frameworks behind modern image generators, are actually the same thing, surfacing three further resources worth reading.
The “same thing” reference: a Google DeepMind explainer showing that diffusion and flow matching can produce identical samples under the right parameterization.
A Kaiming He’s Back to Basics paper from 2025 argues that diffusion models no longer truly denoise but instead predict noise, a harder task. It suggests predicting the clean image directly and shows that simple pixel-level Transformers can achieve similar results without added complexity.
A great intro to flow matching models: Julia Turc’s video breakdown. Paired with the companion diffusion.fyi interactive tutorial, recommended as the cleanest on-ramp before harder papers.
Community take w/ Pierre Chapuis: “Flow matching is just what happens when you realize there is a simpler and better way to do diffusion.”
🎬 CS153 with Black Forest Labs – Stanford’s Frontier Systems class hosted Black Forest Labs co-founder Andreas Blattmann, covering the lab’s image and video generation stack.
Cyber
📐 AISI evaluates Claude Mythos – The UK’s AI Safety Institute tested Claude Mythos Preview on a battery of hacking challenges. It solved the hardest tier 73% of the time, and became the first AI to complete a 32-step simulated corporate network attack entirely on its own, succeeding in 3 of 10 attempts and averaging 22 steps versus 16 for the previous best model. It got stuck on an industrial-controls scenario though, and its performance kept scaling with more compute.
Community take w/ Gabriel Olympie: “As long as it is not independently tested, I consider Mythos a marketing stunt. More seriously, it’s not the first time Anthropic is using cyber to create traction, so even if Mythos is most likely real and quite powerful, I’d wait to see it evolve in the real world before falling for the narrative.”
🔍 Post-Mythos jagged cyber frontier – Security firm AISLE argued Mythos’s capabilities are less exclusive than Anthropic suggests. When they ran Anthropic’s own showcase bugs through small, cheap open-source models, 8 out of 8 caught the main flaw, even a tiny model costing roughly $0.10 per million tokens. Their point: the security workflow around any model matters more than the model itself. AI hacking skills are also uneven: a model can ace a hard bug and then completely miss an easier one.
🛡 GPT-5.4 Cyber for defenders – OpenAI launched GPT-5.4 Cyber, a version of GPT-5.4 tuned for defensive security work with looser safety filters that would normally block legitimate cybersecurity tasks. It can also analyze compiled software without needing the source code, something binary reverse engineers usually do by hand. Access is limited to verified individuals and approved organizations through the Trusted Access for Cyber program.
Language Models
🧠 Qwen 3.6 35B-A3B refreshed – Qwen shipped 3.6 as a 36B-parameter, 3B-active mixture model on Hugging Face with a 262K native context, positioned around agentic coding and a new Thinking Preservation mode that keeps reasoning traces from historical messages to reduce redundant thinking across turns.
🆕 Claude Opus 4.7 ships – Anthropic announced Claude Opus 4.7 as its most capable Opus, pitched for long-running tasks with more rigor, tighter instruction following, and self-verification of outputs, alongside three-times resolution vision, a new xhigh effort tier on the API, and a /ultrareview command in Claude Code. Reception on reddit was sharp: reports of faster token burn, lazy “let’s pick this up later” quitting after a few messages, hallucinated packages and imaginary coworkers, fabricated search tool calls without the UI indicator, sycophancy that flips positions under light pressure, and broad failure to honor configured claude.md and system preferences that 4.6 handled without drift.
Community take w/ Julien Seveno-Pilitant: “Even if the scaling laws still work technically, from a human perspective it makes less and less difference. The models are converging toward the entropy of the language itself, and they approach it logarithmically, so the progress is less and less visible.”
👩💻 Tokenizers tuned for code LLMs – A new paper with Ivan Yamshchikov (Pleias) contribution proposed training tokenizers that focus on widely shared, useful code pieces rather than rare project-specific junk, so models learn durable code patterns more reliably.
Programming
💬 Karpathy on prompt requests – Andrej Karpathy relayed a Peter Steinberger line that PRs should stand for “Prompt Requests”: capable agents can implement most ideas, so there is no need to take an idea, expand it into a vibe-coded mess on free-tier ChatGPT, and send that as a PR. The community pushback was that coding agents still need a second set of eyes, and that specs or markdown files are not the new source code.
🎻 Cline Kanban for multi-agent orchestration – Cline Kanban is a promising open-source UI to orchestrate multiple coding agents (Claude Code, Codex, Cline) in a Kanban board, letting you break down projects, chain dependent tasks, and review real-time diffs and comments in one place.
🎤 Building pi in a world of slop – Mario Zechner’s presentation of pi at AI Engineer Europe, his minimal, extensible coding‑agent harness. He criticized opaque “slop” agent ecosystems and OSS clanker spam, and argues for slow, tightly scoped, human‑controlled use of agents in codebases.
Community take w/ Robert Hommes: “AI Engineer Europe completely altered my beliefs on coding agents. Codex and Claude Code are the wrong harness to run GPT and Claude. Thin harness and heavy skills together with high-intelligence models like Claude, Gemini, and GPT is going to be the real unlock. Removing the developer dependency using skill transfer learning will end developer babysitting and start swarm programming with autonomous agents.”
Robotic, World AI
🤖 Pi07 steerable robotic foundation model – Physical Intelligence released pi07, a steerable model showing strong gains in generalization, including early compositional abilities. It can learn new tasks like using kitchen appliances with step by step language guidance, then execute them autonomously after fine tuning. It also shows cross embodiment transfer, for example folding laundry on a bimanual UR5e without task specific training data. The model supports multimodal prompts, including language, metadata, control signals, and visual subgoals.
🌍 NVIDIA Lyra 2.0 for 3D worlds – NVIDIA Research released Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale from a single image. It fixes the common failure where models forget what spaces look like and lose track of motion over time by maintaining per-frame 3D geometry to retrieve past frames and using self-augmented training to correct its own temporal drift. A robot can be dropped into the generated world for real-time simulation and immersive applications.

👉 Community Ask:
🤖 Luigi d’Ovidio looks for a quick DM with anyone hands-on with Vision-Language-Action model development.
Other topics
⭐ GitHub fake star economy exposed – A peer-reviewed ICSE 2026 study using StarScout identified around 6 million fake stars across 18,617 repositories by 301,000 accounts, with fake campaigns affecting 16.66% of repositories with 50+ stars by mid-2024. Stars sell for $0.03 to $0.85 on at least a dozen open marketplaces, and VCs explicitly use star counts as sourcing signals, with Redpoint reporting a median of 2,850 stars at seed.
👟 Allbirds pivots to AI – Allbirds sold its shoe brand and assets for $39M, locked in a $50M convertible financing facility, and rebranded as NewBird AI to become a GPU-as-a-service and AI-native cloud provider, pending a May 18 stockholder vote.

📊 Stanford 2026 AI Index released – Stanford HAI’s 2026 AI Index laid out ten takeaways: the US–China model performance gap has effectively closed to a 2.7% top-model lead, industry produced over 90% of notable frontier models, generative AI reached 53% population adoption within three years, and AI researcher migration to the US dropped 89% since 2017. It also flagged a jagged capability frontier, with models winning IMO gold while reading analog clocks correctly only 50.1% of the time.
👉 Community topics:
🥷 Lior Oren built a tool using a signed-data anti-fraud patent to catch fake-location candidates in hiring pipelines, triggered by a selfie step, and is looking for design partners to test it for free.
📈 GrowthMom competitive intel tool – Louis Manhes is building a competitive intelligence tool for startups using Clay-style waterfall enrichments across pricing, product, SEO, content, and socials, with an MCP interface for GTM agent stacks.
New Member
🇫🇷 Charles Sonigo – Cofounder @ Alpic · All-in-one MCP platform helping companies build presence in ChatGPT and Claude via tools to build, deploy, test, audit, and monitor MCP servers and ChatGPT apps. Geek turned PM turned founder turned Geek, full loop. Dad, tennis, and wingfoil on the side. Special power: I sleep fast. 📍 Paris, France
Contributors This Week
obert Hommes (Moyai.ai), Pierre Chapuis (Finegrain), Aly Moursy, Gabriel Olympie (2501.ai), Gilles Seghaier (Astran), Julien Seveno-Pilitant, Sebastien Charrier (Bump.sh), Amine Saboni (Pruna.ai), Daniel Madalitso Phiri, Gawen Arab (Airbuds), Ihab Bendidi (Recursion), Lior Oren, Louis Manhes (Genario), Quentin Dubois (OSS Ventures), Guillaume Lesur (Wire), Koutheir Cherni (Guepard), Emmanuel Benazera (Jolibrain), Julien Duquesne (Scienta Lab), Youssef Tharwat (Noodlbox), Andrea Pinto (Notte.cc), Antoine Sueur (Pletor), Charles Sonigo (Alpic), Constant Razel (Hypermind), Jules Belveze, Luigi d’Ovidio (Graybx), Noé Charmet (Shipfox), Sylvain Hajri (Epieos).